GERÊNCIA DE ROTEAMENTO EM REDES INTERCONECTADAS
por
Lisiane Hartmann
Dissertação submetida como requisito parcial para a obtenção
do grau de
Mestre em Ciência da Computação
Profa. Liane Margarida Rockenbach Tarouco
Orientador
Porto Alegre, Janeiro de 1997
CIP - CATALOGAÇÃO NA PUBLICAÇÃO
Hartmann, Lisiane
Gerência de Roteamento em Redes Interconectadas / Lisiane Hartmann. Porto Alegre: CPGCC da UFRGS, 1997.
111 p.: il.
Dissertação (mestrado) Universidade Federal do Rio Grande do Sul. Curso de Pós-Graduação em Ciência da Computação, Porto Alegre, BR-RS, 1997. Orientador: Tarouco, Liane Margarida Rockenbach.
1. Redes de Computadores. 2. Roteamento em Redes de Computadores. I.Tarouco,
Liane Margarida Rockenbach. II. Título.
UNIVERSIDADE FEDERAL DO RIO GRANDE DO SUL
Reitor: Prof. Hélgio Trindade
Pró-Reitor de Pesquisa e Pós-Graduação: Prof. Cláudio Scherer
Diretor do Instituto de Informática: Prof. Roberto Tom Price
Coordenador do CPGCC: Prof. Flávio Rech Wagner
Bibliotecária-Chefe do Instituto de Informática: Zita
Prates de Oliveira
AGRADECIMENTOS
A minha família
pelo carinho e incentivo constantes,
apesar da distância
SUMÁRIO
LISTA DE FIGURAS
LISTA DE TABELAS
LISTA DE ABREVIATURAS
RESUMO
ABSTRACT
1 INTRODUÇÃO
1.1 O Gerenciamento de Redes
1.2 Objetivos e Organização do Trabalho
2 O ROTEAMENTO: SUAS CARACTERÍSTICAS, PROTOCOLOS E PROBLEMAS TÍPICOS
2.1 Aspectos Gerais
2.2 Os Protocolos de Roteamento
2.2.1 RIP - Routing Information Protocol
2.2.2 IGRP - Interior Gateway Routing Protocol
2.2.3 BGP - Border Gateway Protocol
2.3 Problemas Típicos
2.3.1 Hosts não acessam hosts em outra rede
2.3.2 Host não consegue acessar algumas redes
2.3.3 Conectividade disponível para alguns hosts mas não para outros
2.3.4 Alguns serviços disponíveis, outros não
2.3.5 Usuários não conseguem fazer conexões quando um caminho paralelo está inoperante
2.3.6 Roteador vê atualizações de roteamento e pacotes duplicados
2.3.7 Roteador funciona apenas para alguns protocolos
2.3.8 Roteador ou host não alcança nós na mesma rede
2.3.9 Roteadores IGRP não se comunicam
2.3.10 Tráfego não está passando através de roteador utilizando redistribuição
2.3.11 RIP ou IGRP não funcionam em interfaces novas
3 DIAGNÓSTICO DE FALHAS NO ROTEAMENTO
3.1 Ferramentas e Dispositivos de Monitoração
3.1.1 Comandos SHOW
3.1.2 Comandos DEBUG
3.1.3 O PING
3.1.4 O TRACE
3.1.5 O NETSTAT
3.1.6 O SNMP e a MIB II
3.2 Problemas de Roteamento Investigados
3.2.1 A Rota Default
3.2.2 As Métricas
3.2.3 O Desvio de Rotas
4 SISTEMAS ESPECIALISTAS EM REDES
4.1 Aspectos Gerais de Sistemas Especialistas
4.2 A Base de Conhecimentos do MAR
4.3 O Conjunto de Regras
5 IMPLEMENTAÇÃO DE UM MÓDULO DE ANÁLISE DE ROTEAMENTO
5.1 A Implementação do MAR
5.2 Interface com o CINEMA
5.3 Especificação SDL do Sistema
6 CONCLUSÕES E TRABALHOS FUTUROS
ANEXO A-1 BACKBONE DA RNP NO BRASIL
ANEXO A-2 BACKBONE DA REDE TCHE
BIBLIOGRAFIA
Figura 2.1 Exemplo de tabelas de roteamento.
Figura 2.3 Exemplo da convergência lenta no protocolo RIP
Figura 2.4 Exemplo de Rede utilizando IGRP
Figura 2.5 Exemplo de rede com múltiplos caminhos
Figura 2.6 Exemplo de Tabela de Roteamento IGRP
Figura 2.7 Fluxo de informações no BGP-4
Figura 2.8 Um exemplo de ambiente de Interconexão de Redes
Figura 2.9 Host-A não se comunica com Host-B.
Figura 2.10 Exemplo de problema com topologia de caminhos paralelos
Figura 3.1 Diagrama Geral para Resolução de Problemas.
Figura 3.2 Um mapa simplificado da RNP no Brasil
Figura 3.3 O segmento da RNP no RS
Figura 3.4 Segmento da RNP entre RS e SC
Figura 3.5 Mapa simplificado da rede da UFRGS
Figura 4.1 Componentes de um Sistema Especialista
Figura 4.2 Exemplo de uma Rede Semântica.
Figura 5.1 Funcionamento do MAR
Figura 5.2 Exemplo de registro aberto pelo MAR
Figura 5.3 Módulo Principal do MAR
Figura 5.4 Módulo de Monitoração
Figura 5.5 Módulo de Análise de Resultados e Detecção de Problemas
Figura 5.6 Módulo de Integração com o CINEMA
Tabela 2.1: Hosts não acessam hosts em outras redes
Tabela 2.3: Conectividade disponível para alguns hosts mas não para outros
Tabela 2.4: Alguns serviços disponíveis, outros não
Tabela 2.5: Usuários não conseguem fazer conexões quando um caminho paralelo está inoperante
Tabela 2.6: Roteador vê atualizações de roteamento e pacotes duplicados
Tabela 2.7: Roteador funciona apenas para alguns protocolos
Tabela 2.8: Roteador ou host não alcança nós na mesma rede
Tabela 2.9: Roteadores IGRP não se comunicam
Tabela 2.10: Tráfego não está passando através de roteador utilizando redistribuição
Tabela 2.11: RIP ou IGRP não funcionam em interfaces novas
Tabela 3.1: Tabela de roteamento do roteador em Rio Grande
Tabela 4.1: Informações de rotas para a RNP
Tabela 4.2: Informações de rotas para a rede da UFRGS
Tabela 4.3: Informações de rotas para a Rede TCHE
Tabela 4.4: Conjunto de regras dos problemas típicos
Tabela 4.5: Conjunto de regras relativos aos problemas
monitorados
ARP Address Resolution Protocol
BGP Border Gateway Protocol
CINEMA Cooperative Integrated Network Management
EGP Exterior Gateway Protocol
EIGRP Enhanced Interior Gateway Routing Protocol
FTP File Transfer Protocol
ICMP Internet Control Message Protocol
IGP Interior Gateway Protocol
IGRP Interior Gateway Routing Protocol
IP Internet Protocol
IS-IS Intermediate System to Intermediate System
MAR Módulo de Análise do Roteamento
MIB Management Information Base
OSPF Open Shortest Path First
POP Ponto de Presença
RFC Request For Comments
RIP Routing Information Protocol
SDL Specification and Description Language
SMTP Simple Mail Transfer Protocol
SNMP Simple Network Management Protocol
TCP Transmission Control Protocol
TCP/IP Transmission Control Protocol / Internet Protocol
UDP User Datagram Protocol
UFRGS Universidade Federal do Rio Grande do Sul
Com o atual crescimento das redes de comunicação e o surgimento de novas tecnologias que as implementem, a função de roteamento se torna cada vez mais necessária, pois é preciso que as diversas redes possam se comunicar entre si, trocando informações sobre as rotas disponíveis ou mais adequadas. Cada rede possui uma topologia distinta, características específicas de funcionamento e serviços, além de uma variedade de protocolos de comunicação.
Existe hoje no mercado uma variedade de protocolos de roteamento, cada um com suas características e algoritmos próprios de otimização do encaminhamento dos pacotes. Grande parte dos roteadores no mercado conseguem manipular e interagir com vários destes protocolos de roteamento, e esta diversidade torna a tarefa de configuração e gerenciamento do roteamento da rede uma tarefa bastante complexa. A redistribuição de informações de roteamento entre protocolos distintos pode gerar métricas incorretas e estações mal configuradas podem injetar na rede infomrações de roteamento errônea que será propagada pelos protocolos de roteamento.
Face aos problemas que surgem decorrenetes da interconexão cada vez mais crescente das redes de computadores e da função de roteamente, constata-se a necessidade de uma ferramenta de apoio à Gerência de Redes, capaz de auxiliar a detectar automaticamente inconsistências nos mecanismos de roteamento dos dispositivos de interconexão das redes mediante inspeção de suas tabelas de roteamento e antecipar/prevenir falhas decorrentes.
Este trabalho apresenta um estudo
detalhado dos aspectos que envolvem o roteamento, tais como suas características,
protocolos e problemas típicos. Também apresenta algumas
das ferramentas mais utilizadas para a monitoração do roteamento,
e exemplos de monitorações realizadas em alguns roteadores
da rede TCHE e da RNP visando determinar os problemas mais frequentemente
encontrados. O resultado deste trabalho de investigação foi
usado no projeto e implantação de um sistema especialista
monitorador orientado à detecção de possíveis
problemas de roteamento. Aspectos da implementação do MAR
(Módulo de Análise de Roteamento) também são
apresentados, bem como sua integração com o ambiente CINEMA
(Cooperative Integrated Network Management), uma plataforma integrada de
suporte à detecção de falhas, e de registro e acompanhamento
de problemas.
Palavras-chave: Redes de Computadores, Roteamento, Gerência de Redes, Monitoração de Rede, Sistemas Especialistas.
A função de roteamento em redes de computadores é sem dúvida, crítica para a comunicação entre redes interconectadas, pois requisitos de confiabilidade demandam a existência de rotas alternativas e o processo de seleção da melhor rota para o encaminhamento de pacotes necessita ser feito com base em informações muito voláteis e dinâmicas. Com o crescimento e desenvolvimento de redes como a Internet, alterações de topologia e a consequente necessidade de adaptação do roteamento constitui a regra geral e não mais uma exceção. Em função disto, frequentemente surgem alguns problemas no que diz respeito ao roteamento com pacotes sendo encaminhados por rotas totalmente erradas e, em consequência a rede evidencia um comportamento instável. Para tentar solucionar ou pelo menos amenizar estes problemas, novas estratégias tem sido desenvolvidas, bem como tem havido uma adaptação e evolução das já existentes, conforme relatado em [HAR 95].
A principal função de uma rede de comutação de pacotes é receber pacotes de uma estação fonte e enviá-los à sua estação destino [TAN 88]. Para que isto seja possível, determina-se um caminho ou rota através da rede, pelo qual os pacotes serão enviados. Numa rede de pacotes existem muitos nós interconectados e um número de rotas possíveis entre eles. A função de roteamento de uma rede é responsável por decidir sobre qual saída um pacote que chega deve ser transmitido.
A fim de implantar tal função nas redes de computadores, foram desenvolvidos vários algoritmos de roteamento, dos quais alguns se tornaram clássicos e muito conhecidos [TAN 88]. Os protocolos de roteamento implementaram alguns destes algoritmos e são hoje conhecidos e utilizados por muitos equipamentos comerciais. Dentre estes protocolos os que mais se destacam são o RIP, IGRP, BGP, OSPF, além de outros [COM 91]. Cada protocolo possui características específicas e bem definidas, o que determina a sua maior ou menor adequação em função das características e necessidades de cada rede em particular.
Geralmente, os algoritmos de roteamento implementam uma tabela de roteamento em cada máquina, a qual armazena informações sobre possíveis destinos e como alcançá-los. Estas tabelas de roteamento estão presentes em máquinas como roteadores e gateways, e naquelas máquinas da rede que também fazem o roteamento além das suas outras funções. A tabela é consultada toda vez que existe a necessidade de se transmitir um pacote de uma máquina para outra em uma rede qualquer.
Com o passar do tempo, podem ocorrer alguns problemas com estas tabelas, pois a sua utilização e atualização variam de acordo com o protocolo utilizado para fazer o roteamento.
Em redes, e até mesmo subredes interconectadas, podem surgir problemas na propagação de rotas e informações da tabela devido à mistura de protocolos de roteamento utilizados em cada rede, sendo que algumas informações contidas nos pacotes podem ser mal interpretadas quando ocorre a tradução dos dados (métricas, por exemplo) utilizados em um protocolo, para aqueles requeridos em outro.
Um outro problema que aparece é o loop de roteamento, que ocorre quando há falhas nas tabelas de roteamento e um determinado pacote fica então transitando na rede, sem chegar ao seu destino, até que o seu tempo de vida acabe.
A incoerência de rotas é outro problema que ocorre em redes de computadores. Isto pode ser observado através da monitoração do status das tabelas. Um exemplo da incoerência de roteamento é quando se observa que um pacote ou todo um determinado tráfego de pacotes desvia a sua rota por um caminho impossível de ser usado para atingir o destino final do pacote.
Face à existência deste tipo de problema constata-se a necessidade de uma ferramenta de apoio à gerência de rede, capaz de auxiliar a detectar inconsistências nas tabelas de roteamento dos dispositivos de interconexão das redes.
O modelo tracional de gerência de redes pressupõe uma divisão da gerência nos seguintes segmentos: Gerência de Configuração, Gerência de Desempenho, Gerência de Problemas, Gerência de Contabilização, Gerência de Segurança.
Esta forma clássica de gerência de redes tem em todos os seus segmentos, um fator de alta relevância que é a informação, a qual é a base para o processo de gerência que normalmente é constituído das seguintes etapas:
Tratamento dos dados: nesta etapa ocorre a transformação dos mesmos em informações, ou seja, o "dado bruto" passa por processos estatísticos (média, desvio padrão, teoria das filas, etc.) e os valores obtidos são os insumos para a etapa seguinte.
Análise das informações: a análise das informações gerenciais obtidas na etapa anterior é efetuada através de comparações com indicadores previamente estipulados, e tem como finalidade subsidiar a última etapa deste processo.
Ação: esta última etapa consiste em adotar, dentre as alternativas existentes, a medida cabível (ação) para a gerência em pauta.
Verifica-se que quanto mais complexa é uma atividade de gerência, uma maior quantidade de recursos (softwares, hardwares, etc.) se faz necessária para que sua execução seja efetuada de forma automática. Com a necessidade crescente de sistemas que executem a gerência de redes de forma automatizada, tem surgido cada vez mais aplicativos nesta área, dentre os quais, os sistemas especialistas tem se destacado.
Os sistemas especialistas são uma classe de sistemas de Inteligência Artificial desenvolvidos para servirem como consultores na tomada de decisões que envolvem áreas restritas da ciência, normalmente dominadas apenas por especialistas humanos. São sistemas que utilizam o conhecimento de um ou mais especialistas codificado em um programa que o aplica na resolução de problemas.
As tarefas preferenciais para esse tipo de sistema são fundamentalmente as de natureza simbólica, geralmente inviáveis de serem resolvidas pelos procedimentos algoritmicos da computação convencional. Envolvem complexidades e incertezas normalmente só resolvíveis com regras de "bom senso" e com a elaboração de um "raciocínio" similar ao humano.
A capacidade de utilizar conhecimento na resolução de problemas permite que a busca de soluções em problemas complexos seja feita de maneira dirigida, ao contrário da busca por exaustão. O sistema é informado sobre as características do problema e decide, durante o processamento, qual o caminho mais provável de conter a solução. Esta economia de recursos computacionais tem como resultado prático a abordagem de problemas que antes estavam fora do alcance da computação, devido à quantidade e complexidade dos fatores a serem considerados [ABE 94].
Esse tipo de sistema já é utilizado na gerência de redes, pois há uma ampla gama de serviços e novas características que tornam esta atividade complexa e pouco eficiente. Por isso, é necessário conceber sistemas que permitam gerenciar a rede de uma forma inteligente. Neste trabalho será apresentado um protótipo que aplica certas características de sistemas especialistas.
Partindo-se disto, visa-se projetar e implementar uma ferramenta de apoio à gerência de roteamento em redes interconectadas distribuídas, a fim de solucionar os problemas levantados anteriormente.
Ainda como objetivo do trabalho, espera-se integrar a ferramenta desenvolvida ao ambiente de gerência de rede CINEMA - Cooperative Integrated Network Management, especialmente no que tange ao módulo de Registro de Problemas (Trouble Tickets System), que será apresentado posteriormente.
Este trabalho apresenta os resultados do estudo realizado sobre os diversos protocolos de roteamento, seus problemas mais frequentes, bem como o conhecimento adquirido na implementação do MAR (Módulo de Análise de Roteamento). O Capítulo 2 faz uma análise do roteamento e dos protocolos mais utilizados atualmente na Internet, bem como descreve alguns dos problemas típicos que ocorrem em redes conectadas, juntamente com os sintomas e causas mais prováveis. No Capítulo 3 são apresentadas as ferramentas mais utilizadas no diagnóstico de problemas de roteamento e que foram maciçamente aplicadas durante a fase de estudo do comportamento da rede. Ainda neste capítulo estão descritos alguns dos problemas encontrados durante a monitoração da rede e a forma de monitoração empregados. O capítulo 4 conta um breve resumo da técnica de sistemas especialistas aplicados a redes de computadores e apresenta a forma de representação do conhecimento do sistema MAR. Os aspectos relevantes à implementação do MAR, descrevendo o ambiente, a documentação feita em SDL, as saídas do sistema, a integração ao ambiente CINEMA e a avaliação do sistema são apresentados no Capítulo 5. Finalmente, o Capítulo 6 identifica as principais dificuldades encontradas durante o projeto do sistema, faz uma avaliação dos resultados obtidos e apresenta prováveis extensões futuras.
2 O ROTEAMENTO: SUAS CARACTERÍSTICAS, PROTOCOLOS E PROBLEMAS TÍPICOS
O algoritmo de roteamento, conforme apresentado em [COM 91], consiste basicamente nos seguintes passos:
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
Independentemente do tamanho de uma rede, sabemos que o ser humano não é capaz de responder de forma rápida e segura a mudanças de rotas ou recursos da rede. Portanto a propagação automática de rotas não é um mecanismo que permite apenas a divulgação de rotas para o funcionamento coerente de uma rede, mas também um mecanismo de automação de gerência e controle da mesma [GAS 93]. É bastante clara então a necessidade de propagação destas informações de forma rápida e eficiente. Para realizar a propagação automática das informações de roteamento contidas nas tabelas, os protocolos utilizam-se de um dos mecanismos abaixo:
Link State: com esta técnica, ao invés de uma tabela, cada roteador mantém um mapa da topologia da rede. Basicamente, a tarefa de um roteador é testar inicialmente a possibilidade de comunicação com os roteadores diretamente conectados a ele. Obtido o estado do enlace (up ou down), o roteador divulga as informações para outros roteadores. A grande vantagem deste mecanismo reside no fato das mensagens enviadas serem pequenas, o que evita um volume de tráfego desnecessário na rede.
Os protocolos de roteamento estão divididos em dois grupos: os IGPs (Interior Gateway Protocol), e os EGPs (Exterior Gateway Protocol). Um IGP gerencia informações de roteamento dentro de um "Sistema Autônomo", uma coleção de redes sob o controle de uma única autoridade central [NEN 95]. Dentro de um sistema autônomo as informações de roteamento são trocadas usando um protocolo interno escolhido pelo administrador do sistema [CRA 94]. No início das atividades de roteamento, os IGP´s inicializam uma tabela com os endereços das redes diretamente conectadas a eles. Um processo de roteamento recebe as atualizações de outros roteadores da rede e envia suas informações através da rede. Entre os protocolos IGP's, os mais conhecidos e utilizados são o RIP, IGRP, EIGRP, OSPF e IS-IS.
Por sua vez, os EGP's são utilizados na troca de informações de roteamento entre redes que não compartilham uma mesma administração, portanto, pertencem a sistemas autônomos distintos. Dentre os EGP's, podemos citar o BGP e o EGP. As informações passadas entre sistemas autônomos são chamadas "Informações de Alcançabilidade" (reachability information) e mostram simplesmente quais redes podem ser alcançadas através de um sistema autônomo específico. Os detalhes de roteamento dentro de cada sistema autônomo não são propagados, embora sejam enviadas as listas das redes de cada sistema. Os EGP's requerem três conjuntos de informações antes de começarem o roteamento:
As redes baseadas em TCP/IP seguem a premissa de que os roteadores conhecem as rotas corretas porque trocam informações de roteamento entre si. Os hosts por sua vez, apenas aprendem as rotas dos roteadores, sendo que as suas informações de roteamento podem não ser completas. Os hosts são proibidos de repassar informações a outras máquinas. Pode-se dizer então que os roteadores ocupam-se ativamente na propagação de informações de roteamento, enquanto que os hosts adquirem passivamente as informações de roteamento e nunca as propagam.
O protocolo RIP utiliza este conceito provendo dois modos de operação. Os hosts utilizam o RIP no modo passivo, ouvindo as mensagens enviadas pelos roteadores, extraindo as informações de roteamento e atualizando suas próprias tabelas de roteamento. Os roteadores utilizam o RIP no modo ativo, ouvindo as mensagens de outros roteadores, instalando novas rotas em suas tabelas, e enviando mensagens que contém atualizações das informações de sua tabela de roteamento.
A base do protocolo RIP é uma implementação direta do algoritmo de roteamento vector distance para redes locais. Um roteador no modo ativo transmite uma mensagem a cada 30[seg] em todas as interfaces de rede, contendo informações de roteamento correntes. Cada mensagem consiste de pares, onde cada par contém um endereço IP e uma distância para esta rede. RIP usa uma métrica de contador de saltos (hops) para medir a distância até um destino, onde um roteador possui um salto para redes diretamente conectadas, dois saltos para redes que estão alcançáveis através de um outro roteador e assim por diante. Tanto as máquinas ativas quanto as passivas ouvem todas as mensagens de broadcast e atualizam suas tabelas de acordo com o algoritmo vector distance.
Quando um mensagem de atualização chega, a máquina que a recebe examina cada entrada e compara com os dados da sua tabela de roteamento para um mesmo destino D. O receptor utiliza uma desigualdade de triângulos para testar se a rota anunciada para D é superior à rota existente. Isto é, quando examina uma entrada recebida de um gateway G, o receptor R pergunta se o custo de ir para G, mais o custo de ir de G para D, é menor que o custo de ir para D. Em termos matemáticos podemos expressar:
custo(R, G) + custo(G, D) < custo(R, D)
onde custo(i, j) representa o custo do menor caminho entre i para j. O receptor apenas atualiza sua entrada na tabela de roteamento se o custo do tráfego enviado através do gateway G é menor que o valor corrente. Quando troca uma rota, o receptor atualiza o custo para:
custo(R, G) + custo(G, D)
Pelo fato do custo para alcançar um gateway vizinho ser igual a 1, a expressão torna-se:
custo(R, D) = custo(G, D) + 1
Pode-se então simplificar o algoritmo dizendo que:
O protocolo RIP apresenta alguns problemas básicos e instabilidades, e com isto precisa manipular alguns erros causados pelo algoritmo:
Gateways utilizando RIP não podem facilmente detectar loops de roteamento. Quando ocorre um loop para um destino D, o protocolo faz com que os gateways envolvidos incrementem vagarosamente suas métricas. Isto continua até que a métrica alcança o infinito, um valor tão grande que o software de roteamento interpreta como: "nenhuma rota existente para este destino". Para ajudar a limitar os danos causados pelos loops, o RIP define um valor menor para o infinito. Em outras palavras, para limitar o tempo que um loop de roteamento pode persistir, o RIP define o infinito como sendo 16. Quando uma métrica alcança este valor, o protocolo interpreta como "nenhuma rota existente".
RIP requer que todos os roteadores e hosts apliquem um timeout para todas as rotas. Uma rota pode expirar quando ocorre seu timeout. Suponha que um gateway G que participa ativamente da rede fica inativo por algum motivo. Seus gateways vizinhos recebiam mensagens de atualização periodicamente, e rotas instaladas que utilizam G como next hop. Quando o gateway G fica inativo, seus vizinhos não tem como saber que as rotas que utilizam G como next hop precisam tornar-se inválidas. Ou seja, o custo destas rotas deve tornar-se infinito, mas os vizinhos não tem uma forma de aprender sobre esta mudança porque o gateway responsável pelas atualizações está inativo. Dessa forma, quando uma nova rota é aprendida, deve ser associada um timer com ela. Se nenhuma informação é recebida para revalidar a rota antes do seu timeout, declara-se a rota como inválida.
Uma das causas mais comuns do aumento dos loops de roteamento está no fato dos gateways divulgarem todas as informações de roteamento em todas as interfaces. Para ilustrar este último aspecto, considere o exemplo da Figura 2.3. No início, como o gateway B possui uma conexão direta com a Rede A, ele adiciona esta rota na sua tabela de roteamento com a distância igual a 1, e a inclui nas mensagens de broadcast. Com isto, o gateway C aprende que B possui uma rota para a Rede A e então adiciona esta rota na sua tabela, com distância igual a 2, e inclui este caminho nas suas mensagens de broadcast. Finalmente, o gateway D aprende que a rota para a Rede A passa por C e B e a insere na sua tabela, com distância igual a 3 e também passa a divulgá-la nas mensagens de broadcast.
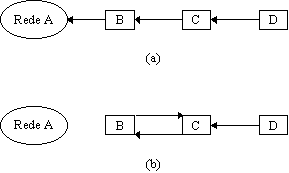
É possível solucionar o problema da Convergência Lenta utilizando uma técnica conhecida como Split Horizon. Quando esta técnica é utilizada, um gateway registra a interface sobre a qual ele recebe a informação sobre uma dada rota e não propaga a sua informação sobre esta rota de volta na mesma interface. Isto significa que a mensagem de broadcast que um gateway manda para o seu vizinho deve omitir as rotas que apontam para o vizinho, evitando assim a formação de loops.
Outra técnica usada para solucionar este problema emprega Hold Down. A regra básica diz que, quando uma dada rota é removida, nenhuma outra rota nova deve ser aceita para o mesmo destino durante um período de tempo (tipicamente 60[seg]). A idéia é esperar um tempo suficiente para que todas as máquinas recebam a informação de falha de conexão. A desvantagem do Hold Down é que se ocorrer loops de roteamento, estes podem ser preservados durante o período de espera, além de serem preservadas todas as rotas incorretas durante este período.
Uma outra técnica que pode solucionar o problema de Convergência Lenta é chamada de Poison Reverse. Quando uma conexão é removida, o gateway responsável pela propagação desta rota retém as entradas por vários períodos de atualização, e inclui um custo infinito no seu broadcast. Para esta técnica ficar mais eficaz, ela deve ser combinada com outra chamada Triggered Updates. Esta força um gateway enviar uma mensagem de broadcast imediatamente após receber uma notícia de falha de conexão, ao invés de esperar pelo próximo broadcast periódico.
Em suma, o protocolo RIP pode ser caracterizado pelo seguinte:
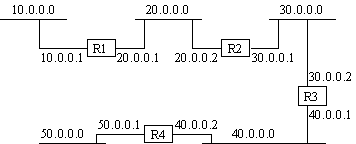
O IGRP é um protocolo que permite aos gateways construir e manter suas tabelas de roteamento através da troca de informações com outros gateways. Um gateway começa sua tabela com entradas para todas as redes diretamente conectadas a ele, e obtém informações sobre outras redes trocando mensagens de atualizações de roteamento com os gateways vizinhos. Em um caso simples, o gateway encontrará um caminho que representa o melhor caminho para alcançar uma outra rede. Um caminho é caracterizado pelo próximo gateway para o qual os pacotes deverão ser enviados, a interface de rede que deverá ser utilizada e informações de métrica. A informação de métrica é um conjunto de números que caracteriza o quanto é a rota é boa, o que permite ao gateway comparar várias rotas que foram adquiridas de vários gateways e decidir qual delas ele deve usar. Existem casos frequentes onde pode-se dividir o tráfego em duas ou mais rotas. O IGRP não fornecerá a informação de que dois ou mais rotas são igualmente boas. O usuário também pode configurar para que o tráfego seja dividido em duas ou mais rotas que são quase igualmente boas. Neste caso, mais tráfego será enviado pela rota que possua a melhor métrica.
A métrica usada pelo IGRP inclui:
Periodicamente cada gateway executa um broadcast de sua tabela de roteamento. Quando um gateway recebe este broadcast de um outro gateway, ele compara a tabela recebida com a já existente. Qualquer novo destino e caminho é adicionado à tabela do gateway. As rotas já existentes na sua tabela são comparadas, e se existir alguma rota melhor, ela pode ser substituída.
Quando um gateway é ligado pela primeira vez, sua tabela de roteamento é inicializada. Isto pode ser feito por um operador em um terminal, ou por leitura de arquivos de configuração. A descrição de cada rede conectada ao gateway é fornecida, incluindo o atraso referente a topologia ao longo do enlace e a largura de banda. Por exemplo, na Figura 2.4 o gateway S poderia comunicar-se com as redes 2 e 3, visto que estão diretamente conectados. Assim que é inicializado, o gateway 2 sabe apenas que pode acessar qualquer destino via redes 2 e 3. Todos os gateways são programados para periodicamente transmitir aos seus vizinhos as informações de roteamento que foram inicializados e as informações coletadas de outros gateways. Sendo assim, o gateway S pode receber atualizações do gateway R e T e aprender que pode acessar a rede 1 através do gateway R e a rede 4 através do gateway T. Desde que o gateway S envie sua tabela de roteamento completa no próximo ciclo, o gateway T aprenderá que pode acessar a rede 1 através do gateway S.
A métrica composta utilizada pelo protocolo pode ser expressada pela relação:
[(K1 / Be) + (K2 * Dc)]r
Onde:
Be é a largura de banda efetiva: largura de banda da rota descarregada x (1 - ocupação do canal)
Dc é o atraso da topologia
r representa a confiabilidade
Dc = Ds + Dcir +Dt
Onde:
Dcir o atraso no circuito (atraso de propagação de 1 bit) e
Dt o atraso de transmissão.
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
Os holddowns são utilizados para prevenir que mensagens de atualização restaurem uma rota com falha. A regra básica afirma que quando uma rota é removida, nenhuma nova rota deve ser aceita para o mesmo destino durante um certo período de tempo. Isto permite que o triggered updates atualize todos os gateways. O período de holddown deve ser grande o suficiente para que a onda de atualizações atinja toda a rede. A combinação de triggered updates e holddowns deveria ser suficiente para solucionar o problema, entretanto existem precauções adicionais para evitar algum dano à rede. São conhecidas como split horizon e poisoning.
O split horizon surge da observação de que nunca enviamos um pacote pela mesma rota na qual ele chegou. As regras do split horizon dizem que uma mensagem de atualização separada deve ser gerada para cada gateway vizinho, sendo que esta deve omitir a rota que aponta para o vizinho. Este mecanismo evita que ocorram laços de roteamento entre roteadores adjacentes.
Por sua vez, o poisoning acaba com laços de roteamento não adjacentes. O aumento da métrica de uma rota geralmente, indica a ocorrência de um loop de roteamento. A reversão remove a rota e a coloca em holddowns. A mensagem é enviada sempre que uma métrica aumenta num fator de 1,1 ou mais.
IGRP mantém uma série de timers e variáveis contendo intervalos de tempo:
A função primária de um sistema falando BGP é permutar informações de alcançabilidade de redes como outros Sistemas Autônomos. A informação de alcançabilidade da rede trocada pelo BGP fornece informações suficientes para detectar loops de roteamento e forçar decisões de roteamento baseadas no desempenho e outros parâmetros. Em especial, BGP troca informações de rede contendo caminhos completos de Sistemas Autônomos e força políticas de roteamento baseadas em informações de configuração.
BGP-4 fornece um novo conjunto de mecanismos para suportar CIDR [FUL 93]. Estes mecanismos incluem suporte para propagar um prefixo IP e eliminar o conceito de classe de rede dentro do BGP. O protocolo introduz também mecanismos que permitem a agregação de rotas, incluindo agregação de caminhos de Sistemas Autônomos [TRA 94].
Para que exista uma conexão entre Sistemas Autônomos é preciso que exista a conexão física propriamente dita e a conexão BGP, que comunica as rotas que podem ser utilizadas para determinadas redes alcançar o Sistema Autônomo. O maior objetivo do BGP é controlar o fluxo do tráfego em trânsito, ou seja, aquele que apenas passa por este Sistema Autônomo.
Visto que o caminho completo do Sistema Autônomo fornece uma forma eficiente e direta de conter loops de roteamento e eliminar o problema do count-to-infinite associado com alguns algoritmos vetor-distância, o BGP não impõe restrições topológicas sobre interconexão de Sistemas Autônomos.
A nível global, o BGP é usado para distribuir informações de roteamento entre múltiplos Sistemas Autônomos. O fluxo de informações pode ser representado conforme a Figura 2.7. A figura aponta que, enquanto apenas o BGP carrega informação entre Sistemas Autônomos, tanto BGP quanto um IGP podem carregar informações através de um Sistema Autônomo.
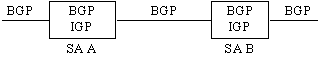
As mensagens de atualização consistem de pares "network-number / AS-path" (número de rede / caminho de AS). O caminho de AS contém a sequência de sistemas autônomos pelos quais uma determinada rede pode ser alcançada. Estas mensagens utilizam TCP para terem uma maior confiabilidade. Os dados trocados inicialmente entre dois roteadores são toda a tabela de roteamento BGP.
BGP não necessita de um refresh periódico de toda a tabela de roteamento, e somente o caminho ótimo é anunciado nas mensagens de atualização. A métrica BGP é um número arbitrário que especifica o grau de preferência de uma determinada rota. Este valor é atribuído pelo administrador da rede através de arquivos de configuração. Na versão 4, pode-se configurar o valor para o atributo de métrica Multi Exit Discriminator (MED). Quando uma atualização é enviada para um par BGP, o MED é passado sem modificação. Assim todos os pares de um AS podem fazer uma seleção de rota consistente.
Algumas premissas básicas utilizadas pelo algoritmo BGP para a seleção de caminhos são apresentadas a seguir:
É muito comum observarmos ambientes de redes heterogêneas, onde existem vários segmentos, cada um com características bem distintas rodando protocolos diferentes. Um ambiente típico é o mostrado na Figura 2.8, que ilustra a interconexão de uma subrede a uma rede corporativa bem como interconexões com redes externas. Percebe-se que os roteadores precisam propagar rotas recebidas de RIP para IGRP, de IGRP para RIP e assim por diante. A nível de usuário, isto deve ser completamente transparente.
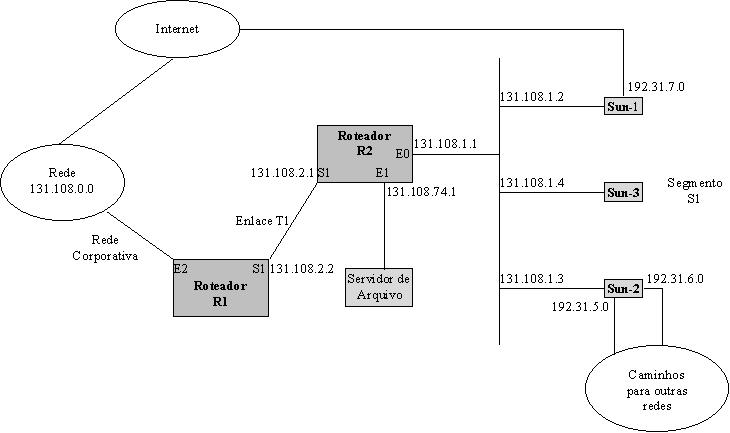
Com tantas interconexões e diversos protocolos, podem surgir alguns problemas de comunicação. Suponha que as estações Sun-1, Sun-2 e Sun-3, conectadas no segmento Ethernet do Roteador-R2 não estão conseguindo se comunicar com hosts na Rede Corporativa principal ou outros pontos através deste roteador. Existem vários caminhos paralelos, os quais permitem que outras redes acessem o Segmento-S1. Pelo fato do acesso externo não estar sendo confiavelmente controlado e devido aos usuários do Segmento-S1 não se comunicarem com a Rede Corporativa pelo Roteador-R2, isto representa os sintomas de um problema de conectividade bem como de segurança. Analisando a situação, os problemas de interconexão podem estar sendo causados por uma redistribuição de rotas ou listas de acesso mal configuradas. O próximo passo é analisar cada uma destas causas como sendo a fonte do problema e então testar a rede para determinar se está operacional depois de cada modificação realizada. A seguir é feito uma análise mais detalhada de cada uma das causas e são apresentadas alternativas para prover um acesso mais adequado e seguro da rede.
Pelo fato dos roteadores baseados em estações UNIX utilizarem RIP e a Rede Corporativa utilizar IGRP, o primeiro aspecto de configuração a ser considerado é a redistribuição de rotas. O Roteador-R2 de redistribuir as rotas IGRP.
O primeiro passo seria analisar a configuração do Roteador-R2. Devido as rotas RIP e IGRP passarem entre a Rede Corporativa e o Segmento-S1, o Roteador-R2 deve estar configurado para fazer a redistribuição destas rotas. Assumindo-se que esta configuração não foi realizada, o passo seguinte seria adicionar os comandos de redistribuição apropriados, conforme apresentados a seguir:
distance 255
network 131.108.0.0
passive-interface serial 1
default-metric 2
redistribute igrp 101
!
router igrp 101
network 131.108.0.0
passive-interface ethernet0
Como terceiro passo, podem ser realizados vários comandos ping do Roteador-R1 para um ou mais do hosts UNIX do Segmento-S1. Assumindo que os controles de acesso estão corretos, o ping deveria funcionar com sucesso, e as estações Sun-1, Sun-2 e Sun-3 deveriam se comunicar com os recursos da Rede Corporativa. O próximo passo é configurar as listas de acesso para permitir que as estações Sun-1, Sun-2 e Sun-3 no Segmento-S1 acessem a Rede Corporativa, mas o acesso seja bloqueado para outras máquinas. A seguir é mostrado uma parte do arquivo de configuração do Roteador-R2 com os comandos adicionais relativos ao controle de acesso da Rede Corporativa.
ip access-group 20
!
access-list 20 permit 131.108.1.2
access-list 20 permit 131.108.1.3
access-list 20 permit 131.108.1.4
Com estas duas alterações feitas no arquivo de configuração, os problemas apresentados estarão resolvidos. É bom observar que existem outras formas de configuração das listas de acesso, mas não serão abordadas. Cabe salientar que a implementação da redistribuição de protocolos é extremamente fácil comparada com a configuração das listas de acesso, que em determinados casos pode se tornar um ponto extremamente complicado na hora da configuração dos roteadores. O arquivo de configuração do Roteador-R2, após as modificações realizadas, é apresentado abaixo:
enable-password noBugZ
!
boot host Router-R2 131.108.2.20
boot system gs3-bf.shell 131.108.2.20
!
interface Ethernet 0
ip address 130.108.1.1 255.255.255.0
!
interface Ethernet 1
ip address 130.108.74.1 255.255.255.0
!
!
interface Serial 1
ip address 131.108.2.1 255.255.255.0
ip access-group 20
!
router rip
default-metric 2
network 131.108.0.0
distance 255
redistribute igrp 101
passive-interface Serial 1
!
router igrp 101
network 131.108.0.0
passive-interface Ethernet 0
!
!
ip domain-name cisco.com
ip name-server 255.255.255.255
snmp-server community
snmp-server community dink RO
snmp-server host 131.108.2.30 dink
access-list 20 permit 131.108.1.2
access-list 20 permit 131.108.1.3
access-list 20 permit 131.108.1.4
hostname Router-R2
!
!
line vty 0 4
login
line com 0
exec-timeout 0 0
password nErdKnoBz
line aux 0
no exec
line vty 0
password nErdKnoBz
line vty 1
password nErdKnoBz
line vty 2
!
end
Nas próximas seções serão apresentados e analisados alguns dos problemas típicos que podem ocorrer com os roteadores, tais como:
É interessante salientar que os estudos realizados basearam-se em roteadores da marca CISCO.

| Possíveis Causas | Sugestões de Ações |
|
Não existe especificação de Gateway Default |
Passo 1. Determinar se existe um gateway
default na tabela de roteamento do host que está tentando fazer
a conexão. Para isto, utiliza-se o seguinte comando UNIX: netstat
-rn, procurando por uma especificação de gateway default
na saída do comando.
Passo 2. Se existir uma especificação incorreta de gateway default, ou se não existir nenhum gateway default definido, é preciso mudar ou então adicionar um gateway default usando o seguinte comando UNIX no host local: route add default address 1 (onde address é um endereço IP do gateway default, o valor 1 indica que o nó especificado está a um hop de distância). Feito isto é preciso inicializar o host para que esta alteração tenha efeito. Passo 3. Para automatizar isto como parte do processo de boot do host, deve-se especificar o endereço IP default do gateway no seguinte arquivo UNIX: /etc/defaultrouter. Este arquivo pode variar de nome conforme a versão do UNIX. Nas redes com PCs ou Macintosh, a forma de definir o gateway default pode ser diferente. |
|
Máscara de subrede mal configurada. |
Passo 1. Verificar nos seguintes arquivos
localizados no host local se a máscara da subrede não está
errada: /etc/netmasks e /etc/rc.local.
Passo 2. Corrigir máscara da subrede se esta estiver especificada incorretamente, ou adicioná-la se não estiver presente. |
| Interface do host está down | Passo 1. Verificar se a interface do host está funcionando. |
| Roteador entre os hosts está down | Passo 1. Utilizando o comando ping,
determinar se o roteador está alcançável.
Passo 2. Se o roteador não responder, isolar o problema e consertar a interconexão inoperante. Passo 3. A seguir são apresentados alguns passos para se obter uma estratégia para isolar os problemas. |
Uma importante consideração a ser feita quando ocorre alguma falha na interconexão de componentes de uma rede é que normalmente os sintomas aparecem em máquinas diferentes e em momentos distintos. Quando aparecem sintomas de falhas, existem alguns passos básicos que podem ser seguidos para tentar isolar suas causas e possivelmente solucionar os problemas. Estes passos devem ser realizados em um host que apresenta os sintomas e são mostrados a seguir:
Passo 2. Utilizar os comandos ping e trace para determinar se os roteadores e bridges através dos quais o host pode se comunicar estão respondendo. Começar os testes com o roteador local e então com outros roteadores da rede.
Passo 3. Se não for possível atravessar um determinado roteador, examinar seu arquivo de configuração e utilizar vários comandos show para determinar o estado do roteador.
Passo 4. Se for possível acessar todos os roteadores no caminho, verificar a configuração do host remoto.
Passo 5. Utilizar comandos show protocol route para observar se o host em questão aparece nas tabelas de roteamento.
| Possíveis Causas | Sugestões de Ações |
| Não existe gateway default | Passo 1. Verificar se existe uma especificação de gateway default correta no host e modificar ou adicionar correta especificação. Isto pode ser feito conforme apresentado já na Tabela 2.3.1. |
|
Lista de acesso mal configurada (recebendo informações de roteamento para alguns roteadores, mas não para outros) |
Passo 1. Utilizando-se o comando show
ip route, verificar a tabela de roteamento e utilizar o comando debug
apropriado (tal como debug ip igrp events e debug ip rip)
para checar as trocas de mensagens entre protocolos.
Passo 2. Procurar informações concernentes à rede com a qual se deseja comunicar. Passo 3. Verificar o uso de listas de acesso nos roteadores do caminho e certificar-se que um comando de configuração do roteador como distribute-list ou distance não filtraram a rota. Passo 4. Remover temporariamente o comando de configuração de interface ip access-group para disabilitar as listas de acesso, e então utilizar o comando trace ou ping com a opção de gravação de rota para determinar se o tráfego pode alcançar o destino enquanto a lista de acesso está removida. |
|
Endereçamento de rede descontínuo devido ao projeto |
Passo 1. Utilizar o comando show ip
route para determinar quais roteadores são conhecidos e quais
precisam ser aprendidos.
Passo 2. Utilizar o comando trace ou ping para verificar onde o tráfego está parando. Passo 3. Fixar a topologia ou redesignar os endereços a fim de incluir todos os segmentos apropriados da rede numa mesma rede principal. Para maiores informações consultar a seção 2.3.5. |
|
Endereçamento de rede descontínuo devido à falha de enlace |
Passo 1. Restaurar enlace desabilitado.
Passo 2. Se ocorre uma falha num enlace, e não é possível utilizar um caminho paralelo, examinar a definição dos endereços de rede. Passo 3. Se a falha no enlace resulta em uma descontinuidade da rede porque uma rede tem diferentes pontos de contato com duas subredes isoladas de uma rede principal diferente, designar endereços secundários ao longo do caminho backup para restaurar a conectividade da rede principal. |
| Possíveis Causas | Sugestões de Ações |
|
Máscara de subrede mal configurada |
Passo 1. Verificar a máscara de
subrede nos hosts e roteadores.
Passo 2. Procurar por um conflito entre máscaras da subrede. O que pode ser um endereço de host específico para um host pode tornar-se uma rede de broadcast quando uma máscara diferente é aplicada ao roteador. Passo 3. Consertar a máscara da subrede no host ou roteador como requerido. As Tabelas 2.1 e 2.8 trazem informações adicionais. |
|
Listas de acesso mal configuradas (host é negado por algum roteador no caminho) |
Passo 1. Determinar onde os pacotes estão
sendo perdidos utilizando-se os comandos trace ou ping através
do caminho.
Passo 2. Se for possível identificar o roteador que está parando o tráfego, utilizar os comandos show access-lists e show ip interface conjuntamente para determinar se estão sendo utilizadas listas de acesso. Passo 3. Desabilitar a lista de acesso temporariamente. Passo 4. Utilizar os comandos ping ou telnet para ver se o tráfego está conseguindo atravessar o roteador. Passo 5. Se o tráfego consegue atravessar o roteador, examine a lista de acesso e os comandos associados para uma autorização apropriada. |
| Perda da especificação do gateway default no host remoto | Passo 1. Com alguém logado no
host remoto, tentar acessar um host fora da rede.
Passo 2. Verificar se a especificação do gateway default no host remoto está correta e modificar ou adicionar uma especificação adequada, conforme apresentado na Tabela 2.1. |
Tabela 2.3: Conectividade disponível para alguns hosts mas não para outros
| Possível Causa | Sugestões de Ações |
|
Lista de acesso extendida mal configurada |
Passo 1. Utilizar o comando trace
para determinar o caminho feito para alcançar os hosts remotos.
Passo 2. (opcional) Em cada roteador do caminho habilitar o comando debug ip icmp. Qualquer roteador que retorna "unreachable" é suspeito. Passo 3. Se for possível identificar o roteador que está parando o tráfego, utilizar os comandos show access-lists e show ip interfaces conjuntamente para determinar se estão sendo utilizadas listas de acesso. Passo 4. Desabilitar temporariamente a lista de acesso. Passo 5. Determinar se o tráfego pode comunicar-se com o roteador. Passo 6. Se o tráfego consegue comunicar-se, revisar a lista de acesso e os comandos associados para uma correta autorização. Em especial, procurar por listas de acesso extendidas que especificam portas TCP. Passo 7. Se uma lista de acesso extendida especifica uma porta TCP, certificar-se que a lista de acesso explicitamente permite todas as portas TCP necessárias. |
| Possíveis Causas | Sugestões de Ações |
|
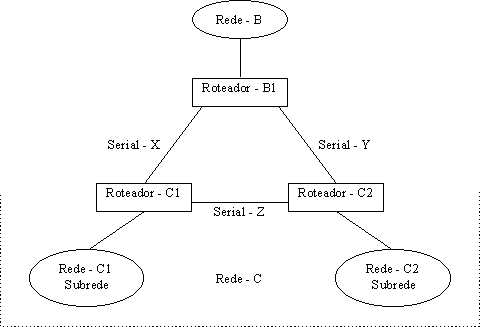
Descontinuidade da rede devido a falha. Se a Serial-Z é perdida, o tráfego não passa da Rede-C1 para a Rede-C2 através do Roteador-B1 |
Passo 1. Tornar o enlace ativo novamente.
Passo 2. Como uma alternativa, usar uma configuração de endereço IP secundário para assegurar que todas as interfaces estão incluídas na mesma rede principal. Com relação à Figura 2.3.5, se a Serial-Z é perdida, a Rede-C torna-se uma rede descontínua, pois o Roteador-B1 está separando as duas subredes C (Rede-C1 e Rede-C2). O tráfego entre o Roteador-C1 e o Roteador-C2 não passará pelo Roteador-B1, pois este assume que eles estão diretamente conectados. |
|
Roteador ainda não convergiu |
Passo 1. Supondo que tem sido usado endereços
secundários, examinar as tabelas de roteamento para rotas que estão
listadas como "possibly down". Se isto for encontrado, o protocolo
de roteamento ainda não convergiu.
Passo 2. Esperar pela conversão do protocolo. Examinar a tabela de roteamento mais tarde. |
|
Listas de acesso mal configuradas ou outros filtros |
Passo 1. Verificar as listas de acesso
no caminho secundário.
Passo 2. Se presente, desabilitar e determinar se o tráfego consegue passar. Se o tráfego atravessa, uma lista de acesso e comandos associados podem estar causando um bloqueio no tráfego. Passo 3. Avaliar e reconfigurar as listas de acesso se necessário. |
| Erros no enlace serial | Passo 1. Utilizar o comando show interfaces serial para observar entradas na interface serial. |
|
Erros no enlace Ethernet |
Passo 1. Utilizar um TDR (Time Domain
Reflectometer) para procurar algum cabo Ethernet aberto.
Passo 2. Verificar os cabos de hosts e transceivers para determinar algum terminação incorreta, muito longa ou danificada. Passo 3. Procurar por um "jabbering tranceiver" conectado a algum host. |
Tabela 2.5: Usuários não conseguem fazer conexões quando um caminho paralelo está inoperante
| Possível Causa | Sugestões de Ações |
|
Bridge ou Repetidor em paralelo com o Roteador causando atualizações e tráfego sendo visto de ambos os lados de uma interface |
Passo 1. Utilizar o comando show ip
routes para examinar rotas de cada interface.
Passo 2. Procurar roteadores remotos conhecidos da rede conectada ao roteador em questão. Roteadores que são listados mas não são conectados a alguma rede diretamente conectada são um provável problema. Passo 3. Procurar caminhos para a mesma rede com o mesmo custo em múltiplas interfaces. Passo 4. Outro teste a fazer é utilizar os comandos debug para examinar rotas de protocolos em cada interface, as quais identificarão tanto a fonte das atualizações de roteamento quanto a interface por onde entram tais informações. Por exemplo, o comando debug ip rip mostra os eventos do protocolo RIP especificamente. Passo 5. Se for constatado a existência de uma bridge em paralelo, desabilitá-la ou configurar a bridge com filtros de acesso que bloqueiem as atualizações de roteamento. |
Tabela 2.6: Roteador vê atualizações de roteamento e pacotes duplicados
| Possível Causa | Sugestões de Ações |
|
Lista de acesso mal configurada |
Passo 1. Utilizar os comandos ping
e trace para ajudar a determinar quais roteadores estão no
caminho e poderiam ser analisados por terem suas listas de acesso mal configuradas.
Passo 2. Utilizar o comando write terminal em um roteador que pode estar parando o tráfego. Passo 3. Procurar alguma lista de acesso na configuração. Passo 4. Desabilitar temporariamente a lista de acesso e monitorar o tráfego através do roteador suspeito. Se o roteador está previamente bloqueando o tráfego, o problema está provavelmente na lista de acesso. Passo 5. Certificar-se que o tráfego desejado está explicitamente permitido; por outro lado, o tráfego não permitido é bloqueado pela declaração implícita do "deny" que termina todas as listas de acesso. |
| Possíveis Causas | Sugestões de Ações |
|
Máscara de subrede mal configurada entre roteador e host |
Passo 1. Testar a conectividade do destino
utilizando o comando ping no roteador e host.
Passo 2. Se for possível "pingar" o roteador local a partir do host local, mas não o host remoto, e se for possível "pingar" o host remoto a partir do roteador local, existe provavelmente um problema de configuração de máscara da subrede no host ou roteador local. Passo 3. Verificar as configurações de máscara de subrede no host e roteador. Certificar-se que todas as máscaras de subrede estão corretas. OBS: Máscaras podem não combinarem se Proxy ARP está sendo utilizado. Para maiores informações sobre a utilização do Proxy ARP são encontradas no RFC1027. Outras informações sobre máscaras de subredes foram apresentadas na Seção 2.3.1. No final desta seção são apresentados alguns aspectos sobre conflitos em máscaras de subrede. |
| Lista de acesso mal configurada | Passo 1. Ver Tabela 2.7 para sugestões de ações. |
|
Nenhum gateway default especificado |
Passo 1. Verificar se a especificação
do gateway default no host remoto está correta e então adicionar
ou modificar a especificação conforme necessário.
Maiores informações foram detalhadas na Tabela 2.1.
Passo 2. Verificar as configurações para rotas estáticas no host e no roteador. Passo 3. Se existe rotas estáticas e nenhum gateway default está especificado, o acesso a alguns hosts pode ser possível, enquanto outros são disponíveis. Existem várias opções para resolver estas inconsistências:
|
|
Especificação de rede incorreta |
Passo 1. Habilitar o comando debug
arp e realizar comandos ping em vários hosts. Procurar
por respostas que indicam uma especificação incorreta de
rede.
Por exemplo, suponha que se tenha um determinado host conectado fisicamente a uma rede ethernet-1 supondo estar conectado a uma rede ethernet-0. Neste caso, pode-se alcançar todos os dispositivos da rede local (ethernet-1), e o roteador consegue enviar os pacotes sem problemas. Entretanto, devido ao endereçamento deste host, o roteador está operando como se ele estivesse conectado à ethernet-0 ao invés da sua correta localização, a ethernet-1. Passo 2. Conectar o host com a sua correta especificação de rede, ou então trocar seu endereço para um número que corresponda ao cabo ao qual está conectado. |
Na maioria das redes IP, roteadores
e hosts deveriam combinar sobre uma máscara de subrede comum. Se
um roteador e um host discordam no tamanho da máscara de subrede,
os pacotes podem não ser roteados corretamente. Como exemplo, considere
as informações genéricas abaixo:
| Informação de Roteamento | Valor do Host | Valor do Roteador |
| Endereço IP destino | 192.31.7.49 | 192.31.7.49 |
| Máscara da subrede | 255.255.255.240 | 255.255.255.224 |
| Endereço interpretado | Endereço de subrede 48, Host-1 | Endereço de subrede 32, Host-17 |
Suponha que um host interpreta um endereço particular (192.31.7.49) como sendo Host-1 na terceira subrede (endereço de subrede 48). Entretanto, por estar usando uma máscara de subrede diferente, o roteador interpreta o endereço como pertencente ao Host-17 na primeira subrede (endereço de subrede 32). Dependendo desta configuração, o roteador bloqueia qualquer pacote destinado para 192.31.7.49 ou envia-os por uma interface de saída errada.
| Possíveis Causas | Sugestões de Ações |
|
A rede está inoperante |
Passo 1. Utilizar o comando ping
para determinar se o roteador está alcançável.
Passo 2. Se o roteador não responder, isolar o problema e reparar a interconexão rompida. |
| Lista de acesso mal configurada | Passo 1. Seguir os passos apresentados na Tabela 2.7. |
| Possíveis Causas | Sugestões de Ações |
|
Falta do comando default-metric |
Passo 1. Utilizar o comando write
terminal para procurar na configuração do roteador o
comandodefault-metric.
Passo 2. Se não existir o comando default-metric, adicioná-lo à configuração utilizando os valores apropriados. |
|
Problema com a distância administrativa default |
Passo 1. Determinar a política
para identificar o quanto as rotas derivadas de diferentes domínios
são confiáveis. Os problemas ocorrem quando uma rota em particular
é, por default, menos confiável que outras, mas atualmente
a rota preferida.
Passo 2. Utilizar o comando de configuração distance para variar o nível de confiança associado com informações de roteamento específicas. |
| Falta do comando redistribute | Passo 1. Verificar a configuração
do roteador utilizando o comando write terminal.
Passo 2. Se o comando redistribute não for encontrado, adicioná-lo à configuração do roteador. |
| Lista de acesso mal configurada | Passo 1. Seguir os passos apresentados na Tabela 2.7. |
|
Comando distribute-list mal configurado |
Passo 1. Utilizar o comando write
terminal para verificar a configuração do roteador.
Passo 2. Certificar-se de que algum comando de configuração distribute-list especifica uma correta lista de acesso. |
Tabela 2.10: Tráfego não está passando através de roteador utilizando redistribuição
| Possível Causa | Sugestões de Ações |
|
Falta do comando de configuração network no roteador |
Passo 1. Utilizar o comando write
terminal para listar a configuração do roteador.
Passo 2. Quando mais de uma rede está configurada em um roteador é preciso adicionar o comando de configuração network. Por exemplo, um roteador que roda IGRP e está ligado a duas redes, suponha que seja 128.10.0.0 e 192.31.7.0, precisa ter os seguintes comandos na sua configuração: network 128.10.0.0 network 192.31.7.0 |
A multiplicidade de protocolos em uso nas redes atuais torna cada dia mais complexa a função de encaminhamento dos pacotes pois a cada protocolo pode corresponder uma diferente estratégia de roteamento. Diferentes protocolos de roteamento podem inclusive ser usados para uma mesma arquitetura de rede, tal como na Internet. Isto ocasiona alguns problemas em função de conversões incorretas de métricas, feitas pelos equipamentos que devem receber informação para nortear o roteamento segundo uma estratégia e encaminhar o pacote por uma rota na qual a estratégia de roteamento é diferente.
As falhas de interconexão derivadas destes problemas podem ser caracterizadas por vários sintomas, sendo uns mais visíveis que outros. Cada sintoma pode ser diagnosticado com base nas possíveis causas ou problemas, usando ferramentas específicas. Após ser identificado, cada problema pode ser solucionado pela implementação de uma série de ações corretivas(solucionar problema) e preventivas (proteger contra reincidência).
Para realmente solucionar um problema, é preciso uma estratégia apropriada. Esta deve seguir alguns passos básicos, tais como identificar os problemas, isolar as possíveis causas, e eliminar sistematicamente cada uma das causas. A Figura 3.1 mostra um modelo deste esquema.
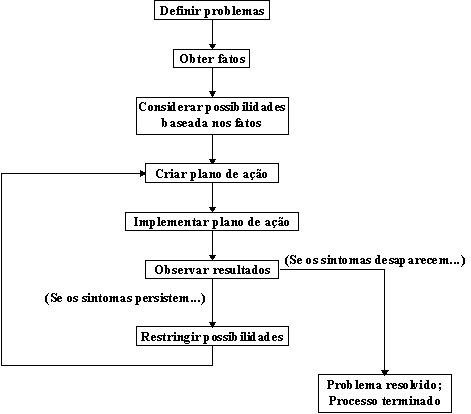
Como segundo passo, é preciso obter fatos (dados), a partir dos sintomas e causas identificados. Isto pode ser obtido através de comandos de monitoração como trace, show, debug, ping, entre outros. A definição do problema apontará um conjunto mais específico de dados a ser obtido.
A seguir é preciso considerar as possibilidades baseadas nos fatos. Com o conhecimento das características e configuração dos roteadores e máquinas da rede, é possível eliminar uma série de problemas associados com o sistema de software e hardware. Desta forma, pode-se dedicar maior atenção àqueles dispositivos, meios, ou máquinas que são relevantes para a solução do problema ou falha.
Feito isto, pode-se criar um plano de ação baseado no conjunto de possibilidades definidos. Este plano de ação deve limitar a manipulação de apenas uma variável por vez, pois isto permitirá que a solução de um problema específico possa ser repetido outras vezes. Se mais de uma variável é alterada simultaneamente, o problema poderá ser resolvido, mas a identificação da alteração específica que eliminou o sintoma pode ser mais difícil.
A próxima fase consiste em implementar (executar) o plano de ação criado no passo anterior.
Com a implementação do plano de ação, deve-se observar os resultados de cada ação executada. Após a manipulação de uma variável, deve-se obter os resultados baseados no plano de ação para se determinar a resolução ou não do problema.
O passo seguinte é restringir as possibilidades baseadas nos resultados. Com estas restrições pode-se formar um conjunto menor de possibilidades, até se obter uma única possibilidade.
Finalmente, deve-se repetir o processo de solução de problemas, enquanto os sintomas persistem. O processo deve ser inicializado com um novo plano de ação baseado em uma nova lista de possibilidades. A resolução do problema pode depender de várias modificações em roteadores, máquinas e meio físico. O processo é enfim terminado quando os sintomas desaparecem, indicando que o problema foi resolvido.
O módulo de análise de roteamento, descrito mais detalhadamente nos próximos capítulos, executa praticamente até o quarto passo do modelo, passando então a responsabilidade de execução para um especialista humano.
Estes comandos são essenciais em qualquer situação de monitoração e detecção de problemas na rede. Os comandos SHOW podem ser utilizados para:
Routing Protocol is "rip"
Sending updates every 30 seconds, next due in 6 seconds
Invalid after 180 seconds, hold down 180, flushed after 240
Outgoing update filter list for all interfaces is not set
Ethernet0/0 filtered by 2
Ethernet0/1 filtered by 2
Serial2/7 filtered by 2
Incoming update filter list for all interfaces is not set
Ethernet0/1 filtered by 1
Serial2/2 filtered by 1
Serial2/7 filtered by 1
Default redistribution metric is 1
Redistributing: connected, static, rip, igrp 2716
Routing for Networks:
143.54.0.0
200.132.0.0
Passive Interface(s):
Serial2/0
Serial2/1
Serial2/2
Serial2/4
Serial2/5
Serial2/6
Passive Interface(s):
Serial2/7
Routing Information Sources:
Gateway Distance Last Update
143.54.1.129 120 0:00:03
143.54.1.254 120 0:00:04
200.132.0.20 120 0:00:12
200.132.0.22 120 0:00:22
200.132.0.19 120 0:00:03
143.54.1.201 120 0:00:03
143.54.1.41 120 0:00:07
143.54.1.30 120 0:00:01
143.54.1.10 120 0:00:07
143.54.1.118 120 0:00:05
143.54.1.119 120 0:00:24
143.54.1.86 120 0:00:11
Distance: (default is 120)
Routing Protocol is "igrp 2716"
Sending updates every 90 seconds, next due in 7 seconds
Invalid after 270 seconds, hold down 280, flushed after 630
Outgoing update filter list for all interfaces is not set
Ethernet0/0 filtered by 2
Incoming update filter list for all interfaces is not set
Default networks flagged in outgoing updates
Default networks accepted from incoming updates
IGRP metric weight K1=1, K2=0, K3=1, K4=0, K5=0
IGRP maximum hopcount 100
IGRP maximum metric variance 1
Default redistribution metric is 10 110000 200 10 1500
Redistributing: connected, static, igrp 2716, igrp 1916
Routing for Networks:
200.132.0.0
Routing Information Sources:
Gateway Distance Last Update
200.132.0.20 100 0:00:33
200.132.0.18 100 0:00:11
Distance: (default is 100)
Routing Protocol is "igrp 1916"
Sending updates every 90 seconds, next due in 3 seconds
Invalid after 270 seconds, hold down 280, flushed after 630
Outgoing update filter list for all interfaces is not set
Incoming update filter list for all interfaces is not set
Default networks flagged in outgoing updates
Default networks accepted from incoming updates
IGRP metric weight K1=1, K2=0, K3=1, K4=0, K5=0
IGRP maximum hopcount 100
IGRP maximum metric variance 1
Default redistribution metric is 10000 100 255 255 1500
Redistributing: connected, static, igrp 2716, igrp 1916
Routing for Networks:
200.136.30.0
200.19.119.0
200.135.0.0
200.132.0.0
Routing Information Sources:
Gateway Distance Last Update
200.135.0.1 100 0:00:01
200.136.30.1 100 0:00:04
200.19.119.65 100 0:00:55 Distance: (default is 100)
Routing Protocol is "bgp 1916"
Sending updates every 60 seconds, next due in 0 seconds
Outgoing update filter list for all interfaces is not set
Incoming update filter list for all interfaces is not set
IGP synchronization is disabled
Automatic route summarization is enabled
Neighbor(s):
Address FiltIn FiltOut DistIn DistOut Weight RouteMap
200.19.119.65
200.131.1.1
200.136.30.1
200.159.255.1
Routing for Networks:
143.54.0.0
192.153.120.0
200.11.8.0
200.11.9.0
200.11.10.0
200.11.11.0
200.11.12.0
200.11.13.0
200.11.14.0
200.11.15.0
200.6.44.0
200.7.0.0
200.7.1.0
200.7.2.0
200.7.3.0
200.9.0.0
200.9.1.0
200.9.2.0
200.9.65.0
150.162.0.0
200.6.47.0
Routing Information Sources:
Gateway Distance Last Update
200.131.1.1 200 4:44:49
200.136.30.1 200 5:37:28
200.159.255.1 200 0:33:50
200.19.119.65 200 0:16:19
Distance: external 20 internal
200 local 200
IP statistics:
Rcvd: 21805860 total, 38030 local destination
2 format errors, 107 checksum errors,
1607 bad hopcount
0 unknown protocol, 23 not a gateway
0 security failures, 0 bad options
Frags: 0 reassembled, 0 timeouts, 0 couldn't reassemble
86102 fragmented, 0 couldn't fragment
Bcast: 28565 received, 57707 sent
Mcast: 0 received, 0 sent
Sent: 72954 generated, 21746368 forwarded
16004 encapsulation failed, 784 no route
ICMP statistics:
Rcvd: 0 format errors, 0 checksum errors,
0 redirects, 65 unreachable
1263 echo, 543 echo reply,
0 mask requests, 0 mask replies, 0 quench
0 parameter, 0 timestamp, 0 info request, 0 other
0 irdp solicitations, 0 irdp advertisements
Sent: 1574 redirects, 1084 unreachable,
575 echo, 1262 echo reply
0 mask requests, 0 mask replies, 0 quench, 0 timestamp
0 info reply, 1455 time exceeded, 0 parameter problem
0 irdp solicitations, 0 irdp advertisements
UDP statistics:
Rcvd: 15794 total, 0 checksum errors, 2381 no port
Sent: 2182 total, 0 forwarded broadcasts
TCP statistics:
Rcvd: 7326 total, 0 checksum errors, 5 no port
Sent: 9052 total
OSPF statistics:
Rcvd: 0 total, 0 checksum errors
0 hello, 0 database desc, 0 link state req
0 link state updates, 0 link state acks
Sent: 0 total
EGP statistics:
Rcvd: 0 total, 0 format errors,
0 checksum errors, 0 no listener
Sent: 0 total
IGRP statistics:
Rcvd: 23619 total, 0 checksum errors
Sent: 55817 total
IGMP statistics: Sent/Received
Total: 0/0, Format errors: 0/0, Checksum errors: 0/0
Host Queries: 0/0, Host Reports: 0/0, DVMRP: 0/0, PIM: 0/0
ARP statistics:
Rcvd: 7129 requests, 292 replies, 137 reverse, 0 other
Sent: 12928 requests, 980 replies (699 proxy), 0 reverse
Probe statistics:
Rcvd: 0 address requests, 0 address replies
0 proxy name requests, 0 where-is requests, 0 other
Sent: 0 address requests, 0 address replies (0 proxy)
0 proxy name replies, 0 where-is
replies
tchepoacs2#debug ip rip
RIP protocol debugging is on
RIP:received update from 143.54.1.11 on Ethernet0
143.54.34.0 in 1 hops
RIP:received update from 143.54.1.10 on Ethernet0
143.54.50.0 in 3 hops
143.54.35.0 in 5 hops
143.54.24.0 in 3 hops
143.54.18.0 in 3 hops
143.54.23.0 in 3 hops
143.54.9.0 in 4 hops
143.54.8.0 in 4 hops
143.54.11.0 in 3 hops
143.54.10.0 in 4 hops
143.54.13.0 in 4 hops
143.54.12.0 in 4 hops
143.54.14.0 in 3 hops
143.54.2.0 in 3 hops
143.54.4.0 in 2 hops
143.54.7.0 in 4 hops
Verificar se um dado componente da rede está ativo é uma das mais básicas atitudes de um gerente quando um problema ocorre. Portanto, o utilitário que permite no mínimo realizar esta tarefa é imprescindível.
Um exemplo de utilização deste comando está apresentada abaixo:
Translating "ESPORA.INF.UFRGS.BR"...
domain server (255.255.255.255) [OK]
Type escape sequence to abort.
Sending 5, 100-byte ICMP Echos to 143.54.7.9,
timeout is 2 seconds:
!!!!!
Success rate is 100 percent (5/5),
round-trip min/avg/max = 4/4/8
ms
Pode ser utilizado para inspecionar situações onde o encaminhamento do pacote IP falhar, tal como um gateway intermediário descarta pacotes; ou implementações de IP intermediários que não suportam registro de rota.
Mostra também o round trip delay entre a origem e o gateway intermediário, para determinar a contribuição de gateways individuais para o delay end-to-end.
Type escape sequence to abort.
Tracing the route to BB2.POP-PI.RNP.BR (200.137.160.129)
1 BB2.POP-SP.RNP.BR (200.136.30.1) 24 msec 20 msec 12 msec
2 BB2.POP-RJ.RNP.BR (200.159.255.1) 104 msec 60 msec 52 msec
3 200.129.0.62 76 msec 60 msec 76 msec
4 BB2.POP-PI.RNP.BR (200.137.160.129) 80 msec * 136 msec
rs>
Conhecer como está o estado da rede, de uma maneira geral e verificar como está sendo realizado o roteamento é muito importante. O comando netstat com os atributos -r e -s juntos, fornece as estatísticas de roteamento.
routing:
87 bad routing redirects
6 dynamically created routes
0 new gateways due to redirects
18 destinations found unreachable
10558 uses of a wildcard route
Routing tables
Destination Gateway Flags Refcnt User Interface
127.0.0.1 127.0.0.1 UH 0 4728 lo0
143.54.8.2 143.54.1.10 UGHD 0 19 le0
143.54.7.18 143.54.1.10 UGHD 0 2731 le0
143.54.1.211 143.54.1.201 UGH 0 0 le0
143.54.7.3 143.54.1.10 UGHD 0 2249 le0
143.54.1.204 143.54.1.201 UGH 0 0 le0
143.54.1.221 143.54.1.201 UGH 0 0 le0
143.54.8.22 143.54.1.10 UGHD 0 4896 le0
143.54.8.0 143.54.1.10 UG 0 31 le0
143.54.48.0 143.54.1.10 UG 0 0 le0
143.54.64.0 143.54.1.10 UG 0 2227 le0
143.54.40.0 143.54.1.10 UG 0 0 le0
143.54.24.0 143.54.1.10 UG 0 207 le0
default 143.54.1.125 UG 16 1173992 le0
143.54.56.0 143.54.1.129 UG 0 1 le0
143.54.17.0 143.54.1.10 UG 0 41 le0
143.54.65.0 143.54.1.10 UG 0 447 le0
143.54.33.0 143.54.1.30 UG 0 0 le0
143.54.9.0 143.54.1.10 UG 0 8421 le0
143.54.25.0 143.54.1.10 UG 0 0 le0
143.54.41.0 143.54.1.10 UG 0 17 le0
143.54.49.0 143.54.1.254 UG 0 0 le0
143.54.57.0 143.54.1.129 UG 0 77 le0
143.54.1.0 143.54.1.20 U 28 479650 le0
143.54.2.0 143.54.1.10 UG 0 13 le0
143.54.10.0 143.54.1.10 UG 0 1180 le0
143.54.42.0 143.54.1.119 UG 0 0 le0
143.54.74.0 143.54.1.10 UG 0 226 le0
143.54.26.0 143.54.1.10 UG 0 0 le0
143.54.34.0 143.54.1.254 UG 0 14490 le0
143.54.58.0 143.54.1.129 UG 0 28712 le0
143.54.35.0 143.54.1.10 UG 0 134 le0
143.54.19.0 143.54.1.10 UG 0 0 le0
143.54.67.0 143.54.1.41 UG 0 110 le0
143.54.11.0 143.54.1.10 UG 0 1756 le0
143.54.3.0 143.54.1.10 UG 3 24199 le0
143.54.27.0 143.54.1.10 UG 0 0 le0
143.54.20.0 143.54.1.10 UG 0 0 le0
143.54.12.0 143.54.1.10 UG 0 8 le0
143.54.36.0 143.54.1.118 UG 0 570 le0
143.54.44.0 143.54.1.86 UG 0 0 le0
143.54.68.0 143.54.1.41 UG 0 0 le0
143.54.4.0 143.54.1.10 UG 1 317 le0
143.54.76.0 143.54.1.10 UG 0 0 le0
143.54.28.0 143.54.1.10 UG 0 0 le0
143.54.13.0 143.54.1.10 UG 0 0 le0
143.54.5.0 143.54.1.10 UG 0 0 le0
143.54.37.0 143.54.1.119 UG 0 24 le0
143.54.61.0 143.54.1.254 UG 0 0 le0
143.54.21.0 143.54.1.10 UG 0 0 le0
143.54.29.0 143.54.1.10 UG 0 0 le0
143.54.45.0 143.54.1.10 UG 0 119 le0
143.54.53.0 143.54.1.10 UG 0 0 le0
143.54.46.0 143.54.1.10 UG 0 0 le0
143.54.54.0 143.54.1.10 UG 0 0 le0
143.54.14.0 143.54.1.10 UG 0 0 le0
143.54.6.0 143.54.1.10 UG 0 322 le0
143.54.126.0 143.54.1.119 UG 0 0 le0
143.54.70.0 143.54.1.10 UG 0 0 le0
143.54.78.0 143.54.1.10 UG 0 0 le0
143.54.22.0 143.54.1.10 UG 0 116 le0
143.54.30.0 143.54.1.10 UG 0 0 le0
143.54.62.0 143.54.1.10 UG 0 0 le0
143.54.55.0 143.54.1.10 UG 0 0 le0
143.54.7.0 143.54.1.10 UG 0 3465 le0
143.54.23.0 143.54.1.10 UG 0 0 le0
143.54.15.0 143.54.1.10 UG 0 0 le0
143.54.47.0 143.54.1.10 UG 0 0 le0
143.54.71.0 143.54.1.10 UG 0 0 le0
143.54.79.0 143.54.1.10 UG 0 0 le0
143.54.31.0 143.54.1.10 UG 0 0 le0
143.54.39.0 143.54.1.10 UG 0 0 le0
143.54.63.0 143.54.1.10 UG 0
0 le0
Os comandos oferecidos pelo SNMP para troca de informações entre o cliente e os servidores são os seguintes:
A divisão das informações de gerência de rede em classes além de padronizar o layout da MIB, tem como objetivo agrupar as variáveis de mesma natureza sob uma mesma denominação. A determinação das classes também é importante pois a cada uma é atribuído um código. A MIB divide as informações de gerenciamento em dez classes, a saber [STA 93]:

Nas próximas seções é feito um detalhamento dos problemas investigados durante o trabalho, bem como a sua forma de monitoração e os procedimentos utilizados durante a fase de observação do comportamento da rede.
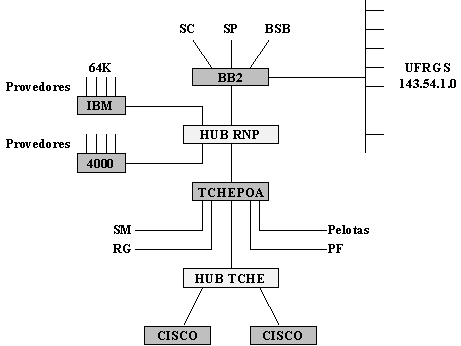
O roteamento default é especialmente útil quando uma rede tem um conjunto pequeno de endereços locais e apenas uma conexão com o restante da Internet. Isto pode ser facilmente observado no caso da RNP, e pode ser visualizado no seu backbone, conforme mostrado no Anexo A-1. Observa-se que os pontos de presença representam a porta de entrada e saída da rede em cada estado. Um exemplo mais simples é o caso da Rede TCHE, mostrada de forma reduzida na Figura 3.3.
snmpi> bulk ipRouteNextHop
snmpi: 96 rows retrieved in 1.033252 seconds during 57 iterations
snmpi: threads: at most 4 active, total of 31 created, and 25 did nothing
snmpi: messages: 127 requests sent, along with 9 retries
snmpi: 127 responses rcvd, along with 0 duplicates
snmpi: timeouts: min=0.022 fin=0.027 max=2.000 seconds
row ipRouteNextHop
0.0.0.0 200.132.0.17
200.6.44.0 0.0.0.0
200.6.44.4 200.6.44.5
200.6.44.8 200.6.44.9
200.6.44.16 200.6.44.17
200.6.44.24 200.6.44.25
200.6.44.28 200.6.44.29
200.6.44.40 200.6.44.42
200.132.0.0 0.0.0.0
200.6.44.56 200.6.44.57
200.132.0.16 200.132.0.20
200.6.44.60 200.6.44.62
200.6.44.68 200.6.44.69
200.238.41.0 200.132.0.18
200.132.0.32 200.132.0.19
200.6.44.72 200.6.44.73
200.238.44.0 200.19.246.17
200.132.0.80 200.132.0.19
200.6.47.0 200.19.246.24
200.238.49.0 200.19.246.30
200.17.82.0 200.6.44.18
200.132.0.128 200.132.0.18
200.17.83.0 200.132.0.18
200.238.51.0 200.19.246.17
200.132.0.208 200.132.0.22
200.17.86.0 200.132.0.18
200.132.0.224 200.132.0.22
200.17.87.0 200.132.0.18
200.238.52.0 200.132.0.18
200.132.1.0 200.19.246.17
200.17.95.0 200.17.172.6
200.238.53.0 200.19.246.24
200.132.2.0 200.6.44.29
200.17.160.0 200.132.0.18
200.238.57.0 200.6.44.58
200.17.161.0 200.6.44.18
200.238.60.0 200.6.44.26
200.132.3.0 200.6.44.61
200.17.164.0 200.6.44.41
200.132.4.0 200.6.44.6
200.17.165.0 200.17.172.3
200.132.5.0 200.6.44.74
200.132.15.0 200.132.0.22
200.17.166.0 200.6.44.74
200.17.168.0 200.6.44.10
200.132.17.0 200.19.246.24
200.17.169.0 200.6.44.6
200.132.224.0 200.6.44.6
200.17.170.0 200.6.44.18
200.132.226.0 200.6.44.6
200.132.227.0 200.6.44.6
200.17.171.0 200.19.246.24
200.17.172.0 200.17.172.1
200.17.173.0 200.19.246.17
200.17.174.0 200.6.44.41
200.132.233.0 200.132.0.18
200.132.240.0 200.6.44.74
200.18.32.0 200.6.44.10
200.132.250.0 200.132.0.18
200.18.33.0 200.6.44.10
200.18.34.0 200.6.44.10
200.18.35.0 200.6.44.10
200.132.252.0 200.132.0.18
200.18.36.0 200.6.44.10
200.18.37.0 200.6.44.10
200.132.253.0 200.132.0.18
200.18.38.0 200.6.44.10
200.132.254.0 200.132.0.18
200.132.255.0 200.6.44.18
200.18.39.0 200.6.44.10
200.18.40.0 200.6.44.10
200.19.241.0 200.6.44.10
200.18.41.0 200.6.44.10
200.18.42.0 200.6.44.10
200.19.250.0 200.6.44.69
200.19.242.0 200.132.0.19
200.19.252.0 200.6.44.18
200.19.245.0 200.19.246.24
200.18.43.0 200.6.44.10
200.19.254.0 200.6.44.6
200.19.246.0 0.0.0.0
200.18.45.0 200.6.44.10
200.19.255.0 200.6.44.6
200.19.246.16 200.19.246.23
200.18.46.0 200.6.44.10
200.18.47.0 200.6.44.10
200.18.67.0 200.19.246.24
200.19.246.64 200.19.246.17
200.18.68.0 200.6.44.6
200.18.75.0 200.132.0.22
200.19.246.80 200.19.246.17
200.19.246.128 200.19.246.17
200.18.76.0 200.19.246.24
200.18.77.0 200.132.0.18
200.18.78.0 200.6.44.18
200.18.79.0 200.6.44.18
snmpi> quit
penta%
snmpi> bulk ipRouteNextHop
snmpi: 24 rows retrieved in 62.119111 seconds during 46 iterations
snmpi: threads: at most 3 active, total of 16 created, and 13 did nothing
snmpi: messages: 40 requests sent, along with 4 retries
snmpi: 40 responses rcvd, along with 0 duplicates
snmpi: timeouts: min=0.083 fin=0.100 max=60.000 seconds
row ipRouteNextHop
0.0.0.0 200.6.44.10
192.168.3.0 200.18.33.33
200.6.44.0 0.0.0.0
200.6.44.8 200.6.44.10
200.17.168.0 200.18.33.34
200.18.32.0 200.18.33.18
200.18.33.0 0.0.0.0
200.18.33.16 200.18.33.17
200.18.33.32 200.18.33.33
200.18.33.112 200.18.33.18
200.18.34.0 200.18.33.18
200.18.35.0 200.18.33.18
200.18.36.0 200.18.33.19
200.18.37.0 200.18.33.19
200.18.38.0 200.18.33.19
200.18.39.0 200.18.33.19
200.18.40.0 200.18.33.19
200.18.41.0 200.18.33.19
200.18.42.0 200.18.33.19
200.18.43.0 200.18.33.19
200.18.45.0 200.18.33.19
200.19.241.0 200.18.33.34
200.18.46.0 200.18.33.19
200.18.47.0 200.18.33.19
snmpi> quit
penta%
Dado a importância da rota default no contexto do roteamento da rede, é preciso haver um constante gerenciamento no que diz respeito a esta rota, já que quando ocorrer alguma anormalidade com ela não se trata de um simples problema, mas de um problema que merece cuidados, já que esta rota determina a saída da rede. Se a default for perdida, a rede pode ficar isolada do restante da Internet.
Se a rota default começar a apontar para destinos diferentes e não especificados nos arquivos de configuração, então está havendo um problema de roteamento. A possível causa pode ser a existência de uma nova máquina na rede, a qual começa a divulgar rotas com métricas default ou então com valores muito baixos, o que faz com que o roteamento seja desviado por ela.
Uma forma de detectar este tipo de problema é gerenciar o objeto da MIB II:
ip.ipRoutingTable.ipRouteEntry.ipRouteNextHop.0.0.0.0
em cada roteador da rede e verificar para onde está apontando. Para o caso da Rede TCHE, é possível determinar as rotas default de todos os pontos da rede. Isto se deve ao fato da topologia da rede ser muito simples e não permitir grandes variações. Através da monitoração da rede e do estudo dos arquivos de configuração dos roteadores da Rede TCHE, foi possível definir suas rotas default conforme apresentado resumidamente abaixo:
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
Através da monitoração dos roteadores pode-se detectar o desvio da rota default. Se isto ocorrer, então tem-se um grande e sério problema de roteamento. Verifica-se que a rota default de Santa Maria, por exemplo, jamais poderá apontar para Passo Fundo, e vice-versa, já que não existe conexão direta, e também não poderá ser desviada para dentro da sua própria rede, o que causaria um isolamento do nó, já que nenhum pacote para fora da subrede estaria saindo para o TCHEPOA.
Um problema interessante aconteceu no início de novembro/96. A rota default do BB2 estava configurada para apontar para a saída de São Paulo (200.136.30.1) ou Brasília (200.19.119.65). De repente, o BB2 parou de repassar via rota default. Foi constatado que a rota default do BB2 estava sendo aprendida via BGP para um endereço estranho (204.189.152.152 - mix-serial3-2.Washington.mci.net). Utilizando-se de ferramentas de monitoração da rede foi percebido o problema, e entre as ferramentas utilizadas estava o comando SHOW:
Routing entry for 0.0.0.0 (mask 0.0.0.0), supernet
Known via "bgp 1916", distance 200, metric 0, candidate default path
Tag 3561, type internal
Last update from 204.189.152.153 00:23:35 ago
Routing Descriptor Blocks:
* 204.189.152.153, from 200.19.119.65, 00:23:35 ago
Route metric is 0, traffic share
count is 1
ip route 0.0.0.0 0.0.0.0 200.136.30.1
Por sua vez, a redistribuição de informações utilizando a métrica default pode degradar a performance da rede. Um exemplo claro disto é a redistribuição de rotas aprendidas por IGRP em um segmento da rede que utiliza RIP. A métrica para todos os nós da subrede RIP não levará em consideração aspectos derivados de diferentes parâmetros considerados pelo IGRP.
Um exemplo do que pode acarretar esta redistribuição de rotas aconteceu a pouco tempo na RNP envolvendo o POP-RS e o POP-SC. Como mostrado na Figura 3.4, existe uma miscelânea de protocolos, sendo que apenas no backbone da RNP é utilizado o IGRP, conforme já mencionado anteriormente. Em conseqüência da entrada de um novo roteador em funcionamento na rede interna da UFSC, o qual passou a divulgar rotas com métricas default muito baixas, foi constatado um desvio do roteamento da rede interna do RS. Com a divulgação de métricas baixas, o roteador do POP-RS começou a repassar as informações e divulgar rotas de saída do estado para Santa Catarina. Com isto, ouve um aumento considerável do tráfego, visto que ao invés de serem repassadas as rotas via São Paulo ou Brasília, começaram a ser desviadas por Santa Catarina. A configuração adequada das métricas default que serão repassadas pelos roteadores é um aspecto crítico durante a fase de configuração em cada segmento da rede.
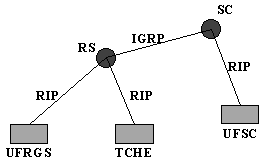
ip.ipRoutingTable.ipRouteEntry.ipRouteMetric1.aaa.bbb.ccc.ddd
onde aaa.bbb.ccc.ddd indica o endereço de rede do qual se deseja monitorar o valor da métrica sendo utilizado. Um exemplo é mostrado a seguir, onde o endereço monitorado é de um segmento da rede da UFRGS:
snmpi> get ipRouteMetric1.143.54.24.0
snmpi: ipRouteMetric1: 3
snmpi> quit
penta%
IGRP: 0 - 16.777.215
BGP: 0 - 65.534
ip.ipRoutingTable.ipRouteEntry.ipRouteProto.aaa.bbb.ccc.ddd
onde aaa.bbb.ccc.ddd é o endereço que se está monitorando.
Para o exemplo apresentado acima, a informação sobre o protocolo obtida é a mostrada abaixo:
snmpi> get ipRouteProto.143.54.24.0
snmpi: ipRouteProto: RIP(8)
snmpi> quit
penta%
Já no caso do IGRP, como o protocolo não permite loops de roteamento, a variação dos valores de métrica podem variar devido a divulgações de métricas erradas ou então de roteadores novos divulgando a métrica default com um valor muito baixo. Analisando-se melhor a expressão que determina a métrica IGRP, pode-se chegar a algumas conclusões interessantes. Representando a métrica como:
Métrica = K1 * BandW + (K2 * BandW) / (256 - carga) + K3 * atraso
E considerando-se os valores default para K1 = K3 = 1 e K2 = K4 = K5 = 0, temos então que a métrica, de uma forma simplificada depende da soma entre largura de banda e atraso:
Métrica = BandW + atraso
Os valores geralmente utilizados como métrica default para a redistribuição do protocolo IGRP, são designados pelo administrador no arquivo de configuração e assumem valores conforme as características da rede. Valores padrões e muito utilizados são os seguintes:
Largura de Banda = 10000;
Atraso = 100;
Alcançabilidade = 255;
Carga = 255;
MTU = 1500.
A frequência de monitoração das métricas no IGRP pode ser considerado como 180 segundos, visto que as mensagens de atualização são repassadas a cada 90 segundos. Se após este período houver mudanças nos valores, deve ser procurada uma causa para esta mudança.
Um caso simples é a tabela de roteamento presente no roteador principal de Rio Grande apresentado na Tabela 3.1. Percebe-se que as informações necessárias são aquelas referentes à rede interna. O roteamento para outros segmentos da rede TCHE, tais como para Santa Maria, Pelotas, UFRGS, RNP e Internet de uma forma mais ampla é totalmente feito através da rota default.
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
Percebe-se que existem dois tipos de roteamento, o local, onde as rotas estão diretamente conectadas ao roteador em questão e o RIP, por onde as rotas são encaminhadas para um próximo roteador. As rotas que não pertencem ao segmento interno são repassadas através da default. Trabalhando-se com uma rede estável, onde não existem caminhos paralelos, é possível determinar este tipo de informação e analisá-la através do estudo da topologia da rede.
Se uma determinada rota ou todo um conjunto de rotas é desviada para um outro caminho, possivelmente existe uma máquina repassando rotas com métricas baixas. Numa rede simples como a examinada, o desvio de rotas seria, com certeza, causado por um problema de roteamento.
Através da monitoração das informações contidas nos principais roteadores, é possível detectar tais problemas. Isto pode ser feito através da utilização do objeto da MIBII:
ip.ipRoutingTable.ipRouteEntry.ipRouteNextHop.aaa.bbb.ccc.ddd
onde aaa.bbb.ccc.ddd é a rota a ser analisada.
Outra forma de monitoração seria através do comando trace. Realizando-se vários traces para diversos hosts presentes nos segmentos que estão tendo suas rotas desviadas, pode-se chegar ao roteador onde está acontecendo o desvio. Maiores detalhes serão apresentados mais tarde nos próximos capítulos.
Um sistema especialista baseado em computadores procura captar o suficiente do conhecimento do especialista humano de modo a também ele solucionar os problemas com perícia. Nos últimos anos, vários grupos de pesquisadores em Inteligência Artificial construíram sistemas altamente especializados contendo a perícia necessária para solucionar problemas de diagnóstico e tratamento médicos, análise de estrutura química, exploração geológica, seleção de configuração de computador e diagnóstico de falhas de computadores, entre outros. Hoje existem sistemas especialistas atuando em áreas como administração, direito, agricultura, informática, eletrônica, engenharia, física, química, geologia, matemática, medicina, e em todas aquelas onde se pode representar o conhecimento de uma forma automatizada.
Podemos dizer que um sistema especialista é composto basicamente por três componentes principais, conforme mostrado na Figura 4.1.
![]()
Já a máquina de inferência é a responsável pela análise do conhecimento e a dedução das conclusões. As máquinas de inferência agregam o conhecimento do especialista humano e utilizam este conhecimento para tentar solucionar um problema.
Por sua vez, a base de conhecimentos contém todos os fatos, idéias, relacionamentos e interações de um determinado domínio. A informação mantida numa base de conhecimentos é organizada em relação a uma evidente estratégia de processamento.
Um dos elementos mais importantes num sistema especialista é o conhecimento. Portanto, é necessário saber como representar e adquirir as informações que irão fazer parte da base de conhecimentos desse sistema especialista. Compreender como a mente humana realmente trabalha na solução de problemas especializados não é necessário para produzir, com êxito, sistemas especialistas que aumentem a capacidade e a produtividade do homem. É suficiente ser capaz de extrair o conhecimento de um ou mais especialistas e de estruturar este conhecimento em uma representação computacional uniforme que permita a aplicação de métodos consistentes de processamento em computador. Isto não significa que seja razoável que, para qualquer problema que requeira especialização, se utilize solução por computador pelas técnicas presentes de sistemas especialistas. Em vez disso, uma extensa classe de problema pode, efetivamente, ser solucionada por estes métodos.
A representação do conhecimento envolve decisões sobre como o conhecimento pode ser estruturado explicitamente, como pode ser manipulado para inferir os dados adicionais e como é feita a aquisição requerida pelo sistema. A escolha de uma representação do conhecimento para uma tarefa particular depende do tipo de problema a ser resolvido e da forma na qual o conhecimento pode ser mais facilmente especificado e utilizado. A aquisição de conhecimento requer duas ações básicas: primeiro, é necessário obter o conhecimento requerido inicialmente para criar a base de conhecimentos; depois, deve haver a manutenção e o aperfeiçoamento do conhecimento.
Existem várias técnicas para a representação do conhecimento, dentre as quais estão as Regras de Produção, as Redes Semânticas, os Frames, as Taxonomias e os Roteiros.
A mente humana possui um amplo estoque de conhecimentos relacionados a uma incontável lista de objetos e idéias. Nossa sobrevivência depende de nossa habilidade em aplicar esses conhecimentos em qualquer situação e aprender continuamente com novas experiências, sendo assim capazes de responder a situações semelhantes no futuro. O que geralmente é considerado inteligência, pode ser dividido numa coleção de fatos e num meio de se utilizar esses fatos para alcançar os objetivos. Isso é feito em parte, pela formulação de conjuntos de regras relacionadas a todos os fatos armazenados no cérebro. As regras de produção descrevem o conhecimento em termos de regras do tipo "SE-ENTÃO" [TAR 90].
As regras são aplicadas em sistemas de produção dentro de um conjunto de uma ou mais bases de conhecimento, de uma estratégia de controle, de uma maneira de solucionar os conflitos que surgem quando várias regras podem ser aplicadas ao mesmo tempo e de um aplicador dessas regras. Um exemplo de regra de produção é o apresentado a seguir:
E o protocolo utilizado é o RIP,
ENTÃO existe um possível loop de roteamento envolvendo máquinas ou segmentos da rede.
As Redes Semânticas por sua vez são representações gráficas do conhecimento. Como uma árvore de decisão, elas consistem em nós que são representados por círculos e arcos formados por linhas com setas. Os nós contém informações e os arcos mostram a relação entre elas. O uso principal das redes semânticas é encontrar relações entre objetos. Um exemplo de uma rede semântica está representado através da Figura 4.2, e mostra a relação entre sintoma e causa de um problema de roteamento, no caso, quando um host não consegue acessar hosts em outra rede.
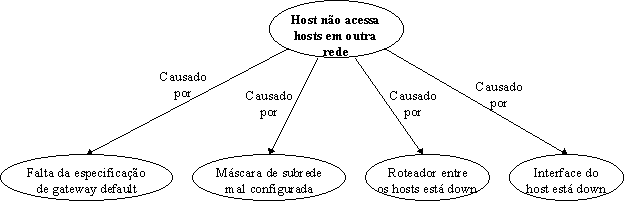
As taxonomias tanto podem descrever conjuntos de informações (como nos frames), quanto podem descrever como a informação está interrelacionada (como nas redes semânticas).
Um roteiro é a representação do conhecimento sobre uma sequência comum de eventos. O roteiro consiste em um conjunto de escaninhos (slots). Informações sobre os tipos de valores de cada escaninho podem estar associadas, bem como um valor default a ser usado caso nenhuma outra informação esteja disponível. O roteiro é muito semelhante a um frame. A diferença é que o roteiro desempenha um papel especializado, podendo-se fazer algumas afirmações mais precisas sobre sua estrutura.
Os sistemas especialistas podem ser classificados em quatro categorias:
A rede TCHE, como já mostrado anteriormente e conforme apresentado no Anexo A-2, é uma rede de configuração simples, com rotas bem definidas. Através de um monitoramento constante da rede, analisando as tabelas de roteamento dos principais roteadores da rede, juntamente com o estudo dos arquivos de configuração, foi possível criar uma baseline com as principais informações de roteamento. Observou-se que o roteamento para determinado destino possui praticamente um único caminho a seguir. Isto facilita a construção da base de conhecimentos.
Um dos roteadores mais monitorados e observados foi o BB2, por ser este a porta de entrada e saída da rede para o restante da RNP. Observou-se que sua tabela de roteamento é muito dinâmica, chegando a possuir em torno de 1700 entradas. Constatou-se que a monitoração contínua de todas as rotas existentes na tabela poderia degradar a performance da rede, além do que não seria necessário monitorar continuamente todas as possíveis rotas. A fase seguinte para a criação da baseline foi a determinação de quais rotas deveriam ser monitoradas pelo sistema de forma contínua. Com isto, reduziria-se o número de monitorações realizadas.
Constatou-se que as rotas para os
pontos de presença em outros estados do Brasil significavam rotas
importantes e deveriam ser monitoradas. O passo seguinte foi descobrir
quais os endereços dos segmentos da RNP nos demais estados. Através
de ferramentas como whois, nslookup, e mapas do backbone da RNP conseguidos
via Internet, foi possível chegar a um conjunto de rotas essenciais.
Com este conjunto em mãos, foram feitas monitorações
das informações contidas no BB2, tais como nexthop, métricas
e protocolo. Estas informações foram agrupadas num banco
de dados e estão representadas na Tabela 4.1 abaixo.
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
Com relação as rotas relativas à rede TCHE, optou-se por monitorar aquelas que representam um papel importante. Estas rotas dizem respeito aos pontos principais da rede e consistem dos endereços para os segmentos em Santa Maria, Passo Fundo, Rio Grande, Pelotas, e PUC-RS. Verificou-se que pela topologia da rede, todas deveriam apontar para o TCHEPOA, menos a rota para a PUC-RS, a qual possui uma conexão direta com o BB2.
Outro conjunto de rotas importante é o que diz respeito à rede da UFRGS. Percebe-se que existe um fluxo considerável de pacotes entre UFRGS e Internet. Levando-se em consideração este fator, constatou-se a importância de se monitorar as rotas para a UFRGS, visto que as mesmas não podem ser desviadas para o interior da rede TCHE, já que a UFRGS possui uma conexão direta com o BB2. Por ser uma rede de topologia relativamente simples e constante, não existindo a presença de caminhos paralelos, chegou-se a uma baseline apresentada aqui através da Tabela 4.2.
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
Além destes conjuntos de rotas, constatou-se a importância de se monitorar as rotas referentes ao nó folha conectado ao POP-RS. As rotas para o estado de Santa Catarina devem obrigatoriamente passar pelo BB2. Estas por sua vez não podem ser direcionadas para dentro da Rede TCHE, nem para outro segmento de rede no estado. Com isto verifica-se a necessidade de se monitorar também este conjunto de rotas, que devem ser repassadas diretamente para o endereço do POP-SC, qual seja, 200.135.0.0.
Além do BB2, outro roteador
importante na rede estadual é o TCHEPOA. É ele que conecta
os principais pontos da Rede TCHE com o BB2, que por sua vez está
conectado com o restante da RNP e Internet. No caso do TCHEPOA, o conjunto
de rotas a ser monitorado é reduzido. Na realidade, ele precisa
apenas possuir em sua tabela de roteamento, as entradas para os pontos
da rede tais como Santa Maria, Passo Fundo, Rio Grande, Pelotas, entre
outros. As rotas para a UFRGS, o restante da RNP e Internet são
roteadas através da default, que necessariamente deve estar apontando
para o BB2. O TCHEPOA de certa forma, confina o tráfego da rede
TCHE, evitando assim que pacotes internos passem a ser roteados pelo BB2
e transitem através da rede. A Tabela 4.3 apresenta as entradas
principais da baseline do TCHEPOA, no que diz respeito à Rede TCHE.
|
|
|
|
|
|
|
|
|
|||
|
|
|
|||
|
|
|
|||
|
|
|
|||
|
|
|
|||
|
|
|
|||
|
|
|
|
|
|
|
|
|
|||
|
|
|
|||
|
|
|
|||
|
|
|
|||
|
|
|
|||
|
|
|
|||
|
|
|
|||
|
|
|
|
|
|
|
|
|
|||
|
|
|
|||
|
|
|
|||
|
|
|
|||
|
|
|
|
|
|
|
|
|
|||
|
|
|
|||
|
|
|
|||
|
|
|
|
|
|
|
|
|
Para o caso dos problemas típicos apresentados no Capítulo
2, pode-se resumir as regras como apresentado na Tabela 4.4. Percebe-se
que as recomendações para solucionar tais problemas já
foram apresentados de forma detalhada através das tabelas contidas
nas seções relacionadas do Capítulo 2. Por esta razão,
não serão apresentadas novamente na tabela abaixo, apenas
sendo indicado a tabela correspondente.
| Problema apresentado | Causas Prováveis | Recomendações |
|
Hosts não acessam hosts em outra rede |
1. Não existe especificação
de Gateway default.
2. Máscara de subrede mal configurada. 3. Interface do host está down. 4. Roteador entre os hosts está down. |
Ver Tabela 2.1 |
|
Host não consegue acessar algumas redes |
1. Não existe gateway default definido.
2. Lista de acesso mal configurada (recebendo informações de roteamento para alguns roteadores, mas não para outros). 3. Endereçamento de rede descontínuo devido ao projeto. 4. Endereçamento de rede descontínuo devido à falha de enlace. |
Ver Tabela 2.2 |
|
Conectividade disponível para alguns hosts mas não para outros |
1. Máscara de subrede mal configurada.
2. Listas de acesso mal configuradas (host é negado por algum roteador no caminho). 3. Perda da especificação do gateway default no host remoto. |
Ver Tabela 2.3 |
| Alguns serviços disponíveis, outros não | 1. Lista de acesso extendida mal configurada. | Ver Tabela 2.4 |
|
Usuários não conseguem fazer conexões quando um caminho paralelo está operante |
1. Descontinuidade da rede devido a falha.
2. Roteador ainda não convergiu. 3. Listas de acesso mal configuradas ou outros filtros. 4. Erros no enlace serial. 5. Erros no enlace Ethernet. |
Ver Tabela 2.5 |
| Roteador vê atualizações de roteamento e pacotes duplicados | 1. Bridge ou Roteador em paralelo com o roteador causando atualizações e tráfego sendo visto de ambos os lados de uma interface. |
Ver Tabela 2.6 |
| Roteador funciona apenas para alguns protocolos | 1. Lista de acesso mal configurada. | Ver Tabela 2.7 |
|
Roteador ou host não alcança nós na mesma rede |
1. Máscara de subrede mal configurada
entre roteador e host.
2. Lista de acesso mal configurada. 3. Nenhum gateway default especificado. 4. Especificação de rede incorreta. |
Ver Tabela 2.8 |
| Roteadores IGRP não se comunicam | 1. A rede está inoperante.
2. Lista de acesso mal configurada. |
Ver Tabela 2.9 |
|
Tráfego não está passando através de roteador utilizando redistribuição |
1. Falta do comando que especifica o valor para
métrica default.
2. Problema com a distância administrativa default. 3. Falta do comando de redistribuição. 4. Lista de acesso mal configurada. 5. Comando de redistribuição mal configurado. |
Ver Tabela 2.10 |
| RIP ou IGRP não funcionam em interfaces novas | 1. Falta do comando de configuração que especifica as redes diretamente conectadas. | Ver Tabela 2.11 |
Estas regras foram selecionadas baseadas em problemas que frequentemente aparecem no ambiente de redes interconectadas. Através de debates entre administradores de redes, pesquisa nos manuais dos roteadores analisados e monitorações constantes da rede, foi possível definir o conjunto de regras acima. Percebe-se que a forma de monitoração e detecção deste tipo de problema exige a interação do especialista humano. Isto pelo fato das ferramentas de monitoração utilizadas para a detecção das falhas interagirem diretamente através de uma interface com o usuário. Dentre as ferramentas utilizadas encontram-se o ping, trace, os comandos show, comandos debug, netstat, entre outras. Devido a este fato, este conjunto de regras não será utilizado na implementação do protótipo, mas podendo ser utilizado mais tarde num módulo de aperfeiçoamento do mesmo.
Para a implementação
do MAR, será utilizado um conjunto de regras derivado dos problemas
apresentados no Capítulo 3, e que dizem respeito aos problemas de
roteamento investigados através de monitorações da
rede utilizando agentes SNMP e objetos da MIB II. Este conjunto é
apresentado na Tabela 4.5.
|
|
|
|
| A rota default está sendo desviada para outra saída | 1. O nexthop relativo à rota default
pode estar inoperante.
2. Pode estar havendo conflitos de protocolos de roteamento. 3. A especificação para a default pode estar errada no arquivo de configuração. |
Verificar o estado das conexões do roteador
e dos enlaces, principalmente o enlace da interface relativa a rota default.
Analisar o arquivo de configuração e verificar se existe a especificação de uma rota default. Através de comandos show (sh ip route 0.0.0.0), verificar se a rota default está sendo repassada e como está sendo aprendida. |
| Ausência da rota default na tabela de roteamento | 1. Não existe a especificação
da rota default no arquivo de configuração.
2. Perda da especificação da rota default. |
Adicionar ou modificar a especificação do gateway default. Feito isto, inicializar o roteador para que a alteração tenha efeito. |
| A rota para a rede aaa.bbb.ccc.ddd está sendo desviada ou não existe a rota na tabela de roteamento | 1. A conexão com o nexthop relativo a
esta rede pode estar inoperante.
2. Máquina divulgando métricas baixas. |
Verificar se as conexões com esta rede
estão operantes. Verificar se as interfaces do roteador estão
operantes.
Realizar pings e traces para a rede em questão para certificar-se de que todos os roteadores no caminho estão operantes. Verificar se a própria rede está operante. Analisar através de comandos show (sh ip route aaa.bbb.ccc.ddd) como as métricas estão sendo aprendidas e qual o valor que está sendo repassado. Certificar-se de que estão sendo repassadas com o protocolo correto. |
| Métrica RIP para determinada rede aumentando a cada monitoração | 1. Loop de roteamento entre duas máquinas ou segmentos da rede. | Verificar a existência de loop de roteamento entre máquinas ou segmentos da rede. Utilizar comandos ping e trace para verificar onde está ocorrendo o loop. Feito isto, detectar o motivo e estabelecer a conexão. |
| Métrica IGRP variando a cada monitoração para uma determinada rota | 1. Pode haver algum roteador novo na rede repassando
rotas com valores de métrica default muito baixos.
2. Alteração nas características da rede que interferem na métrica IGRP, tais como largura de banda de algum segmento, atraso, carga da rede, etc. |
Verificar de quem o roteador está recebendo
as atualizações das rotas e os valores das métricas.
Utilizar os comandos ping e trace para verificar as características da rota, tais como atraso e caminho seguido. Veriicar se houve alguma alteração na topologia da rede ou nas características que podem interferir diretamente no valor da métrica IGRP. |
Tabela 4.5: Conjunto de regras relativos aos problemas monitorados
Os problemas de roteamento especificados por estas regras podem ser todos detectados através da monitoração da rede através de um módulo de análise, não sendo necessária a intervenção direta de um especialista humano durante o processo de análise dos dados. O próximo capítulo apresenta a implementação de um módulo de análise de roteamento que utiliza este conjunto de regras e a base de dados apresentada anteriormente na monitoração da rede e detecção de problemas de roteamento.
O mecanismo de apoio à operação de gerenciamento da rede constitui a ferramenta mais importante para rastrear e resolver problemas. Um esquema deste tipo deve incorporar as seguintes características [TAR 96]:
O núcleo do CINEMA consiste de um monitor que executa como um processo em background e, via SNMP, recupera informações de gerência dos nodos da rede. Tais monitorações são enviadas aos módulos especialistas para a verificação do comportamento da rede e detecção de eventuais problemas. O CINEMA é composto por dois sistemas:
Sistema de Alertas: que provê meios para a monitoração da rede, através do polling periódico de indicadores em um conjunto determinado de componentes da rede. Para que as situações críticas possam ser determinadas, o sistema trabalha com limites, os quais determinam o intervalo no qual os indicadores amostrados estão situados.
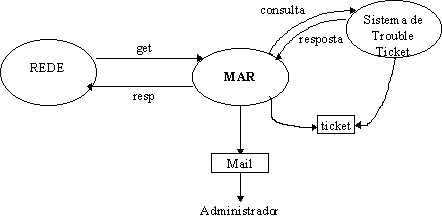
Após um período exaustivo de estudo e monitoração do comportamento da rede e dos seus roteadores, foi possível criar uma base de dados contendo informações relevantes de vários pontos da rede, com as quais se pode definir aspectos para um correto roteamento. Entre estes dados, pode-se destacar as informações sobre a rota default, as rotas mais importantes da rede e suas métricas associadas, como já apresentado no Capítulo 4.
Criado o banco de dados, pode-se monitorar a rede em pontos estratégicos e comparar valores com os armazenados no banco de dados. Com isto, pode-se determinar possíveis anormalidades e indícios de problemas decorrentes de algum fenômeno estranho. Quando o MAR consulta a base de regras e verifica uma anormalidade, ele alerta o usuário responsável através de um mail, e conforme a gravidade do problema é aberto um ticket no CINEMA.
O sistema foi programado utilizando-se a linguagem C, visando simplificar sua integração aos módulos restantes, e conta hoje com aproximadamente 3000 linhas de código entre módulos e bibliotecas. Considerando que o sistema não iria utilizar intensamente os mecanismos de recursividade inerentes à linguagens específicas para IA, tal como PROLOG ou LISP, o resultado foi satisfatório do ponto de vista de funcionalidade e de performance. O uso de uma destas linguagens poderia redundar em performance deteriorada, conforme alerta [SCO 91] ou o sistema apresentar problemas de portabilidade.
O ambiente de redes de computadores utilizado foi a RNP em conjunto com a Rede TCHE. Na fase inicial foram feitos contatos com vários administradores dos diversos pontos das redes a fim de ser feito um levantamento de características e configurações. Os vários roteadores da rede foram monitorados e seus arquivos de configuração estudados.
Para as monitorações foi utilizado o protocolo SNMP, sendo utilizado o pacote de software CMU da Carnegie Mellon University, por ser este um aplicativo de domínio público obtido através de FTP anonymous. Foi escolhido este pacote pela facilidade de integração com a linguagem C, escolhida para o desenvolvimento.
O banco de dados escolhido para dar suporte ao sistema é o POSTGRES [STO 90], visto que o mesmo já é utilizado pelo ambiente CINEMA no seu Sistema de Trouble Tickets.
O CINEMA utiliza uma interface WWW, com senha de acesso a todas as pessoas envolvidas na administração da rede e no projeto como um todo. Isto permite também um acesso ao sistema de qualquer parte da Internet, não restringindo o seu acesso a uma única máquina ou segmento. Por estar constantemente em funcionamento, pode-se afirmar que se trata de um sistema de registro de problemas on-line. Com isto, é possível visualizar sempre uma lista de ocorrências abertas, bem como acompanhar a evolução e resolução de alguma falha.
Um registro pode ser manipulado através de três operações: abrir, emitir notas a seu respeito e fechar. Cada uma destas ações são realizadas em momentos específicos na existência de um ticket. Quando um problema ocorre, o ticket é aberto, contendo alguns campos que definem o problema, tal como mostrado abaixo:
O MAR por sua vez, faz a abertura de tickets, preenchendo os campos citados acima baseado nas informações obtidas e no resultado das análises realizadas. No campo de observações, além de uma explicação do problema, são apresentadas algumas sugestões a serem seguidas para a resolução da falha.
No período de teste do protótipo foram realizadas monitorações nos dois roteadores principais da rede TCHE, o BB2 e o TCHEPOA. As monitorações foram realizadas a cada hora, e neste período, detectou-se a presença de um problema de roteamento. Como já mencionado no Capítulo 3, houve um problema com a rota default (0.0.0.0) do BB2, e um registro foi gerado após serem realizadas três monitorações num intervalo de 180 segundos. A princípio, conforme a baseline da rede, a rota default deveria estar sendo repassada através do protocolo IGRP e deveria apontar para as saídas de São Paulo (200.136.30.1) ou Brasília (200.19.119.65). Mas como constatado, a rota default começou a ser aprendida através do protocolo BGP, e apontar para um endereço estranho (204.189.152.153). A Figura 5.2 apresenta o Registro de Ocorrência realizado pelo MAR.
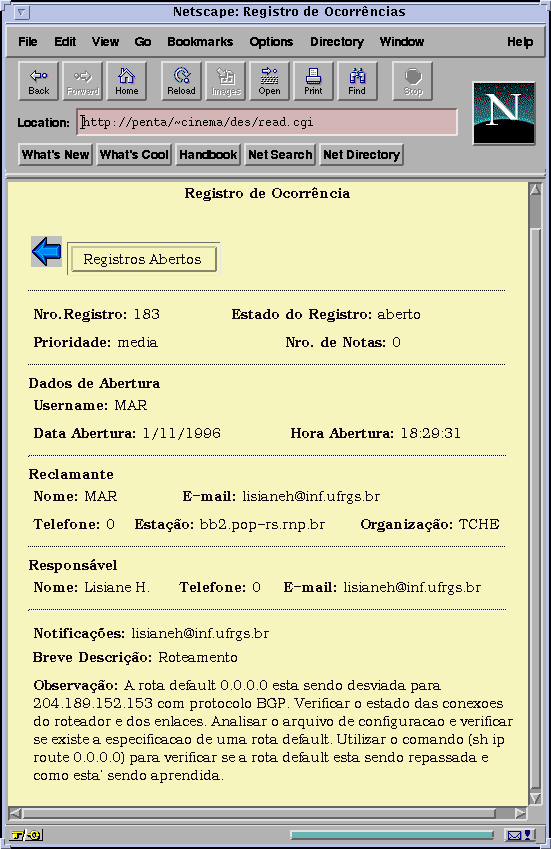
Date: Fri, 1 Nov 96 18:22:07 EDT
From: lisianeh (Lisiane Hartmann)
To: lisianeh
Subject: MAR
Content-Length: 44
Status: RO
X-Lines: 1
Roteador: 200.132.0.17 está com a rota para a rede: 0.0.0.0 desviada por 204.189.152.153
Precisa ser analisada pois está
com problemas.
Date: Tue, 28 Jan 1997 14:14:48 -0300
From: trouble_tickets@penta.ufrgs.br
Subject: criacao de trouble-ticket
Content-Length: 133
X-Lines: 7
Status: RO
Sistema de trouble-tickets
Aviso de criacao de ticket
Numero do Ticket = 183
Autor do ticket: MAR
Descricao do Ticket: Roteamento
Como SDL permite duas formas de representação, gráfica (SDL/GR) e textual (SDL/PR), a escolhida para a representação do MAR foi a gráfica (SDL/GR - Graphical Representation), já que ambas são equivalentes.
O MAR foi implementado através de módulos. O módulo principal é responsável por gerenciar as monitorações, o módulo de monitoração realiza as monitorações propriamente ditas utilizando SNMP e os objetos da MIB II. O módulo de análise de resultados e detecção de problemas utiliza as regras apresentadas anteriormente para detectar possíveis problemas que possam estar ocorrendo. E finalmente, o módulo de integração com o CINEMA realiza a abertura de um registro de problema baseado nas informações de problemas encontrados. Estes módulos estão apresentados a seguir.
Módulo Principal
O módulo principal está representado na Figura 5.3. Inicialmente são feitas algumas inicializações. O procedimento "inicializaBD()" faz a inicialização do banco de dados Postgres, informando a porta e a base de dados a ser utilizada. A inicialização da MIB é feita através do procedimento "init_mib()". A seguir é inicializado um vetor de rotas, onde cada componente do vetor contém o encaminhamento de um arquivo de configuração de rotas. As diversas rotas estão divididas em arquivos que correspondem a um conjunto de redes. Por exemplo, todas as rotas referentes a Rio Grande estarão reunidas em um arquivo, o qual poderá ser chamado de "rio-grande.txt". Quando houver um novo conjunto de rotas a ser monitorado, este apenas deverá ser incluído no vetor de rotas.
A seguir é chamado o módulo "monitora(rota)", que realiza as monitorações nos diversos roteadores da rede e compara os resultados com os obtidos através da baseline de roteamento. Se for encontrado alguma anormalia, indicando algum tipo de problema, é então chamado um módulo de análise de resultados,o "analisa(prob)". Se depois de realizada a análise constatar-se a necessidade de abertura de um ticket, este é aberto através do procedimento "abre_reg(ticket)", caso contrário, é apenas enviado um mail ao responsável indicando que existe uma anormalidade no roteamento, isto utilizando-se o procedimento "envia_mail()".
Como o MAR é um módulo que monitora a rede constantemente, o sistema sempre está rodando, não tendo finalização. Na realidade, o sistema é disparado a cada hora, e quem gerencia isto é o módulo de monitoração.
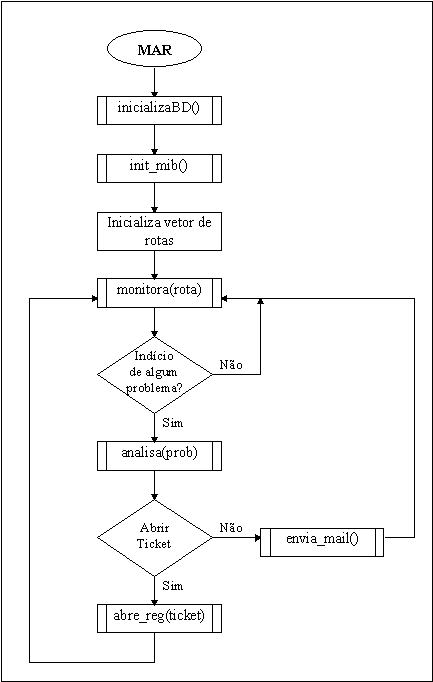
A Figura 5.4 apresenta o módulo de monitoração do sistema. Este primeiramente faz a leitura do arquivo de rotas através do procedimento "le_ende()", armazenando os endereços em um vetor. O disparo da monitoração é feito através do procedimento "dispara_proc()", que dispara o processo de monitoração a cada hora. Quando o processo é disparado, são feitas monitorações nos roteadores especificados utilizando-se SNMP e os objetos da MIB II conforme já apresentados no Capítulo 3. Os resultados obtidos são comparados com aqueles constantes na baseline de roteamento, realizados através de consultas às informações no banco de dados. Isto é realizado através dos procedimentos "compara_rota()", que realiza as comparações referentes às rotas, e o "compara_metrica()", que faz comparações com as informações referentes às métricas. Se for encontrado algum indício de problema, como alguma informação contraditória, é então retornado ao módulo principal uma matriz de erros, contendo a rota analisada, juntamente com as informações adquiridas da rede.
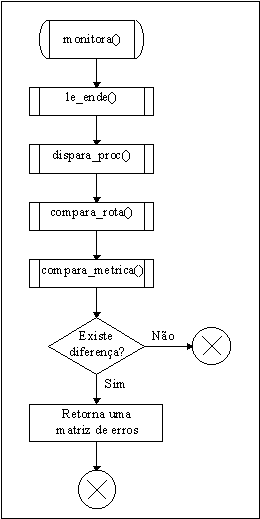
O módulo de análise de resultados e detecção de problemas está representado na Figura 5.5. Quando este módulo recebe uma matriz de erros, isto significa que pode estar ocorrendo algum problema de roteamento. Primeiramente é verificado qual o tipo de falha detectado através do procedimento "verifica_tipo()". O tipo de falha indica se o problema é em relação a um desvio de rota, problemas com a rota default, ou ainda variações de métricas nos protocolos RIP e IGRP. Este tipo é definido com base nas informações contidas na matriz de erros. Por exemplo, quando a matriz retorna o valor de um endereço e a sua métrica RIP variando, possivelmente está havendo um loop de roteamento. Neste caso, um registro do problema deve ser gerado. Quando for retornado um conjunto de endereços e um valor de "nexthop" diferente da baseline, deve ser criado um registro de problema, pois deve estar havendo um desvio de todo um conjunto de rotas. Já no caso de se ter apenas um endereço do conjunto com "nexthop" alterado, apenas deverá ser enviado um mail para o responsável indicando o fato. A abertura de um registro ou o envio de um mail é indicado através de uma variável de controle. É bom notar que este módulo só é acionado quando existir alguma alteração nas informações adquiridas nos roteadores.
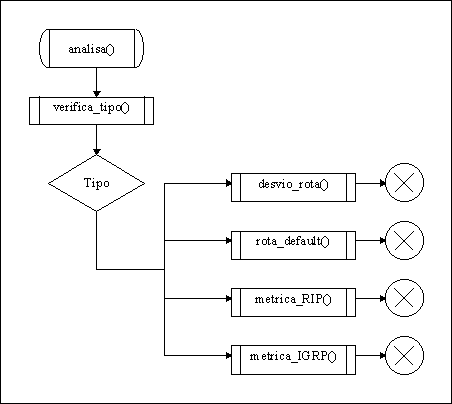
Por fim, o módulo de integração com o ambiente CINEMA está representado através da Figura 5.6. Antes de mais nada é preciso abrir uma conexão com o Sistema de Trouble Ticket. Isto é feito através do procedimento "conecta_CINEMA()", o qual informa o usuário e senha do sistema, além da máquina onde está rodando o sistema e a porta TCP a ser utilizada. Em seguida, é feito uma pesquisa na lista de tickets abertos, para verificar se já existe um registro aberto para este problema. Se existir, é enviado um mail para o responsável. Caso contrário, são preenchidos os campos componentes de um registro, conforme apresentado anteriormente, e então aberto o registro propriamente dito. Feito isto, deve-se então fazer a desconexão com o Sistema de Trouble Ticket através do procedimento "desconecta_CINEMA()".
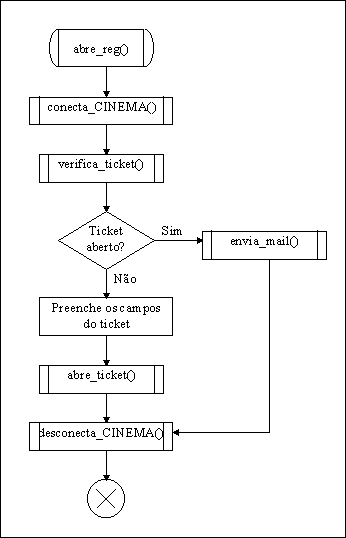
Através deste trabalho foi possível perceber a complexidade que envolve a função de roteamento, bem como a correta configuração e o gerenciamento dos dispositivos de interconexão de redes. O crescimento das redes de computadores e o surgimento de novas tecnologias que as implementem fazem com que o papel do roteamento se torne cada vez mais indispensável.
Analisando-se o funcionamento dos protocolos de roteamento, percebe-se que estes implementam alguns dos algoritmos clássicos, como o Vector Distance e o Link State. Também são utilizados diferentes conceitos e parâmetros para se definir o "custo" de uma comunicação, o que é chamado de métricas. Cada protocolo utiliza estas métricas de forma diferente, pois possui características específicas e bem definidas, o que determina a sua utilização numa rede de computadores.
Levando-se em consideração a diversidade de protocolos de roteamento utilizados nas diversas redes conectadas, é possível perceber a complexidade de conviver com todos sem maiores problemas. A configuração dos roteadores também não é uma tarefa muito fácil. Com isto, tem surgido uma necessidade cada vez mais visível de se ter ferramentas que realizem a monitoração e o gerenciamento do roteamento de forma automatizada, auxiliando administradores de uma forma geral a resolverem os problemas que surgem nesta área. A grande parte dos roteadores possui ferramentas que possibilitam a sua monitoração. Algumas ferramentas principais foram estudadas e utilizadas durante o processo de monitoração da rede. Estas monitorações foram realizadas em alguns roteadores da RNP e Rede TCHE.
Foram realizados vários estudos
e monitorações do comportamento do roteamento na rede, utilizando-se
as ferramentas apresentadas e o estudo dos arquivos de configuração
dos roteadores. Com isto pôde-se detectar algumas falhas de roteamento
e alguns problemas típicos, que foram analisados e discutidos com
pessoal técnico experiente. Com isto, foi possível agrupar
alguns destes problemas, relacioná-los as suas possíveis
causas e determinar um conjunto de ações com o intuito de
resolvê-los. O resultado deste trabalho serviu de base para o projeto
e implementação de um sistema especialista capaz de auxiliar
administradores da rede na tarefa de gerenciamento do roteamento.
O sistema projetado, foi denominado de MAR-Módulo de Análise de Roteamento. Ele utiliza o protocolo SNMP para buscar os objetos da MIB II num processo de monitoração periódica da rede, a fim de detectar indícios de algum problema relativo a roteamento. Os resultados são analisados e um diagnóstico é então desenvolvido podendo gerar mensagens de alerta para os administradores da rede ou diretamente abrir registro de ocorrência de problemas.. Este módulo foi integrado ao Sistema de Trouble Ticket do ambiente CINEMA, podendo gerar automaticamente um registro do problema encontrado.
O protótipo foi implementado num ambiente UNIX, usando a linguagem C e utiliza como suporte o ambiente CMU-SNMP para acesso aos objetos gerenciados dos roteadores. Também foi utilizado o banco de dados POSTGRES para armazenar os dados de baseline coletados e que são consultados no processo de diagnóstico.
O trabalho realizado pode ser utilizado em qualquer outro contexto, bastando instalar o MAR e os módulos do CINEMA e CMU-SNMP. Portanto, esta dissertação tronou disponível uma ferramenta de acompanhamento e monitoração de problemas de roteamento que poderá ser usada emqualquer outra instituição. O protótipo projetado e desenvolvido constitui uma primeira abordagem ao problema e pode ser complementado.
Como sugestão para futuros trabalhos e extensões, está a possibilidade de fazer com que o MAR adquira experiência, aprendendo e agregando conhecimento através da aprendizagem pela análise dos problemas ocorridos. Outro aspecto seria incorporar a possibilidade de agir quando ocorre um problema na tentativa de solucioná-lo atuando diretamente sobre os arquivos de configuração dos roteadores com problema. O conjunto de regras apresentados também pode ser melhorado, acrescentando-se outras regras relativas a novos problemas que forem sendo obseravdos ao longo do tempo.
Concluindo, este trabalho foi válido tanto no aspecto em que proporcionou um estudo abrangente dos protocolos de roteamento e dos problemas que surgem nesta área, quanto possibilitando o desenvolvimento do MAR, que agrega parte do conhecimento adquirido através da observação e monitoração da rede.
ANEXO A-1 BACKBONE DA RNP NO BRASIL
ANEXO A-2 BACKBONE DA REDE TCHE

[CIS 94] CISCO SYSTEMS, Inc.. Internetwork Design Guide.Cisco Systems Inc., Janeiro, 1994.
[CIS 95a] CISCO SYSTEMS, Inc.. Troubleshooting TCP/IP Connectivity. Cisco Systems Inc. 1995.
[CIS 95b] CISCO SYSTEMS, Inc.. Routing Basics. Cisco Systems Inc. 1995.
[CIS 95c] CISCO SYSTEMS, Inc. Routing Protocols. Cisco Systems Inc. 1995.
[COM 91] COMER, Douglas E. Internetworking With TCP/IP: Principles, Protocols, and Architecture. Englewood Cliffs, NJ: Prentice-Hall, 1991.
[HAR 95] HARTMANN, Lisiane. Um Estudo sobre Algoritmos, Protocolos e Novas Tendências para Roteamento em Redes de Computadores. Porto Alegre: CPGCC - UFRGS, 1995. Trabalho Individual.
[HED 88a] HEDRICK, C. Routing Information Protocol. Request For Comments 1058, DDN Network Information Center, SRI International, Junho, 1988, 33p.
[HED 88b] HEDRICK, C. Introduction to Administration of an Internet-based Local Network. Rutgers State University of New Jersey, Center for Computer and Information Services, Setembro, 1988, 37p.
[HED 91] HEDRICK, C. L. An Introduction to IGRP. Center for Computer and Information Services, Laboratory for Computer Science Research, Rutgers University, August, 1991.
[HUI 95] HUITEMA, C. Routing in the Internet. Englewood Cliffs, NJ: Prentice-Hall, 1995.
[HUN 94] HUNT, Craig. TCP/IP - Network Administration. Sebastopol, CA: OReilly & Associates Inc., 1994.
[LEI 93] LEINWAND, A.; FANG, K. Network Management: A Practical Perspective. Working, England: Addison-Wesley, 1993.
[MAD93] MADRUGA, E. L.; TAROUCO, L. M. R. Trouble Ticketing in a Cooperative Integrated Network Management Enviroment. In: IV IFIP/IEEE INTERNATIONAL WORKSHOP ON DISTRIBUTED SYSTEMS: OPERATIONS AND MANAGEMENT, Outubro, 1993, Long Branch, NJ, EUA. {\bf Case Studies}. Long Branch, NJ:[s.n], Outubro, 1993, DSOM'93.
[MAD 94] MADRUGA, E. L. Ferramentas de Apoio á Gerência de Falhas e Desempenho em Contexto Distribuído. Porto Alegre: CPGCC - UFRGS, 1994. Dissertação de Mestrado.
[MCC 90] McCLOGHRIE, K.; ROSE, M. T. Structure and Identification of Management Information for TCP/IP - Based Internets. DDN Network Information Center, SRI International. Request for Comments 1213, March, 1991. 70 p.
[NEM 95] NEMETH, E.; SNYDER, G.; SEEBASS, S.; HEIN, T. R.. Unix System Administration Handbook. Upper Saddle River, NJ: Prentice-Hall, 1995.
[POS 81] POSTEL, J. Internet Protocol. Request For Comments 791, DDN Network Information Center, SRI International, Setembro, 1991, 45p.
[REK 94a] REKHTER, Y.; GROSS P., eds. Application of the Border Gateway Protocol in the Internet. Request For Comments 1655, DDN Network Information Center, SRI International, Julho, 1994, 19p.
[REK 94b] REKHTER, Y.; LI, T.; eds. A Border Gateway Protocol 4 (BGP-4). Request For Comments 1654, DDN Network Information Center, SRI International, Julho, 1994, 56p.
[RIC 94] RICH, E. ; KNIGHT, K. Inteligência Artificial. 2.ed. São Paulo: Makron Books, 1994.
[ROS 91] ROSE, M. T. The Simple Book: An Introduction to Management of TCP/IP - Based Internets. Englewood Cliffs, NJ: Prentice-Hall, 1991.
[SCO 91] SCOTT, A. C. A practical Guide to Knowledge Acquisition. Reading, Massachusetts: Addison-Wesley, 1991.
[STA 93] STALLINGS, W. SNMP, SNMPv2, and CMIP: The Practical Guide to Network-Management Standars. Reading, Massachusetts: Addison-Wesley Publishing Company, 1993.
[STE 94] STEVENS, W.R. TCP/IP Illustrated - Volume 1: The Protocols. Reading, Massachusetts: Addison-Wesley Publishing Company, 1994.
[STO 90] STONEBRAKER, M. POSTGRES Reference Manual. Berkeley, CA: University of California, 1990.
[TAN 88] TANENBAUM, Andrew S. Computer Networks. Englewood Cliffs, NJ: Prentice-Hall, 1988.
[TAR 90] TAROUCO, L. M. R. Inteligência Artificial Aplicada ao Gerenciamento de Redes de Computadores. São Paulo: USP - Escola Politécnica, 1990. Tese de Doutorado.
[TAR 96] TAROUCO, L. M. R. Um Ambiente para Gerenciamento Integrado e Cooperativo. In: Simpósio Brasileiro de Redes de Computadores, 14., 1996, Fortaleza. Anais ... [S.l.:s.n],1996.
[TER 87] TERPLAN, K. Communication Networks Management. Englewood Cliffs, NJ: Prentice-Hall, 1987.
[TRI 92] TRINDADE, R. S. Um Estudo da Linguagem SDL para Especificação e Teste de Protocolos. Porto Alegre: CPGCC/UFRGS, 1992. (TI-258).