No começo, os usuários de computadores tinham que programar o sistema com o uso de chaves de comutação para definir os endereços das máquinas e inserir informações. Com o passar dos tempos, a linguagem assembler foi desenvolvida de modo que os usuários pudessem usar alguns símbolos e instruções simples para programar as máquinas. Hoje em dia, as linguagens de programação de alto nível aceitam instruções em inglês, que são fáceis de entender. Com as linguagens mais novas, os usuários de computador não têm que se preocupar mais em saber endereços de memória específicos para variáveis - podem referir-se a eles simplesmente através dos nomes das variáveis.
Essa analogia também é verdadeira na interligação em rede. Em vez de ter que endereçar um host específico através de seu endereço numérico, é mais fácil usar um nome simbólico. Esse método melhora a produtividade porque os usuários cometem menos erros. Isso também ajuda na identificação do local e do tipo de recurso que uma determinada máquina fornece.
Qual designador de máquina é mais fácil de entender: Servidor de Banco de Dados de Clientes ou 199.246.41.8? Com base no nome, você pode dizer facilmente que a máquina pertence ao departamento de Atendimento ao Cliente e que é um servidor de banco de dados. Mas ao olhar para o número IP, seu palpite é pode ser qualquer um! Outra vantagem em acessar um recurso através do nome é que seus usuários não terão que saber se você moveu aquele serviço fisicamente de uma máquina para outra.
Por exemplo, ao usar nomes, seus usuários irão se conectar ao Servidor de Banco de Dados para acessar os arquivos de banco de dados. Se algum dia você decidir mover os arquivos de banco de dados de um host com o endereço IP 199.246.41.15 para outro host com o endereço IP 199.246.41.17, terá simplesmente que alterar o mapeamento do nome para o endereço IP. Seus usuários não irão nem notar. Contudo, se você usar endereços IP, terá que informar a todos os usuários sobre a alteração - um possível pesadelo no gerenciamento.
É fácil atribuir um nome a qualquer máquina em sua instalação. Contudo, como você poderá garantir que ele será único? Em geral, se você não estiver conectado com o mundo exterior, como a Internet, e em um local relativamente pequeno, terá boas chances de controlar a atribuição de nomes e cada nome que usar será único. Contudo, logo que você se unir a uma rede nacional, ou mesmo regional, as máquinas sob controles administrativos diferentes sofrerão conflitos em relação a nomes. Mesmo se você não se unir a qualquer rede externa, como poderá evitar que nomes duplicados venham a ser usados em sua empresa enquanto sua rede IP crescer?
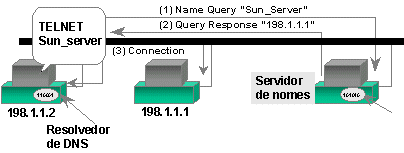
Há duas maneiras para implementar uma tabela de pesquisa de nomes para endereços IP. Você pode ter uma tabela local para cada estação de trabalho ou uma centralizada para todos os usuários. A solução da tabela local é ideal para um pequeno número de usuários ou para quando você quer que cada usuário seja capaz de usar sua própria convenção de atribuição de nomes. Tal implementação é conhecida como tabela de hosts local. Contudo, você não tem controle direto sobre o conteúdo do arquivo porque ele reside em todas as máquinas. Quando uma alteração for necessária, será preciso atualizar todas as máquinas. A vantagem desse método é que se um usuário desordenar sua tabela de hosts, ele não afetará nenhuma outra tabela.
A solução ideal é usar algum tipo de sistema de atribuição de nomes centralizado que traduza nomes para endereços IP. Se uma administração centralizada for usada juntamente com um banco de dados, não haverá chances de duplicação. O maior inconveniente desse esquema é que se você cometer um erro, ele afetará todos os usuários, ao contrário da implementação da tabela de hosts local.
A Internet tomou exatamente essa abordagem para gerenciar sua grande quantidade de nomes. Inicialmente, o "namespace" (ou espaço de nomes) da Internet era contínuo. Cada nome consistia em uma seqüência de caracteres, sem outra estrutura. Embora isso tenha simplificado a atribuição de nomes, a Internet logo achou que o namespace contínuo poderia facilmente lidar com grande quantidade de nomes que existem hoje. Até 1990, havia mais de 137.000 nomes de hosts registrados na Internet [ARN 94].
Enquanto o número de hosts registrados crescia, a carga de trabalho envolvida na manutenção da atualização da quantidade de tráfego para um único local acumulava. Para resolver esses problemas, um esquema de atribuição de nome hierárquico, denominado DNS (Domain Name System), foi desenvolvido. Para ajudar a reduzir o gargalo do tráfego e adicionar redundância a todo o sistema, foi decidido que o namespace seria dividido em domínios diferentes, com cada um tendo máquinas de mapeamento de nomes para o endereço IP.
O DNS é usado principalmente para a conversão de nomes para endereços. Não deve ser confundido com NIS (Network Information Services). O NIS faz mais do que converter nomes para endereços, ele também fornece informações ao usuário, como a user id (uid - identificação do usuário) e a group id (gid - identificação do grupo).
![]()
![]()