No capítulo anterior já foram explicados alguns aspectos importantes do DNS, incluindo a arquitetura cliente-servidor, e a estrutura da base de dados DNS. Entretanto, ainda năo foram dados muitos detalhes.
Neste capítulo serăo esclarecidos os mecanismos que fazem o DNS funcionar. Também serăo introduzidos alguns termos técnicos sobre DNS, que facilitam certas explicaçőes.
3.1 O Espaço de Nomes de Domínio
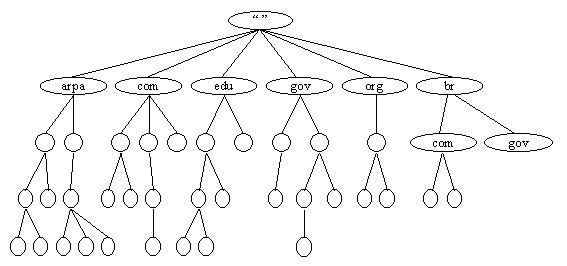
Cada unidade de dado na base distribuída do DNS é indexada pelo nome. Esses nomes săo essencialmente apenas caminhos em uma enorme árvore invertida, chamada de espaço de nome de domínio (em inglęs, "Domain Name Space"). Como já foi mencionado no capítulo anterior, a estrutura hierárquica da árvore, mostrada na figura 3.1, é muito parecida com a estrutura do sistema de arquivos UNIX. A árvore tem uma raiz simples no topo. No UNIX, ela é chamada de diretório raiz (ou root), e representada pela barra ("/"). Em DNS, ela é simplesmente chamada de "a raiz", ou "o domínio raiz". Como um sistema de arquivos, a árvore de DNS pode ter quantos caminhos se necessitar em cada interseçăo, chamada nodo. A profundidade da árvore é limitada em 127 níveis, que é um limite muito difícil de se alcançar.
Cada nodo na árvore é chamado por um nome simples (sem pontos). Este nome pode ter até 63 caracteres de comprimento. O domínio raiz tem um nome nulo (sem comprimento, com tamanho zero), o qual é reservado. O nome de domínio completo de qualquer nodo na árvore é a seqüęncia dos nomes simples em todo o seu caminho até a raiz. Nomes de domínios săo sempre lidos a partir do nodo em direçăo ŕ raiz (árvore acima), e com pontos simples separando os nomes no caminho.
Se o domínio raiz realmente aparece no nome de domínio de um nodo, o nome parece como se estivesse terminado em um ponto (na verdade termina com um ponto, o separador e um nome nulo). Quando um domínio raiz aparece ele é escrito com um ponto simples, por maior convenięncia. Conseqüentemente alguns programas interpretam um ponto final em um nome de domínio para indicar que o nome de domínio é absoluto. O nome de domínio absoluto é escrito relativamente a raiz. Isto especifica a localizaçăo de um nodos sem ambigüidade na hierarquia. Um nome de domínio absoluto é também referenciado como um nome de domínio totalmente qualificado, as vezes abreviado como FQDN, do inglęs Fully Qualified Domain Name. Nome sem ponto no fim săo as vezes interpretados como nome de domínios relativos, assim como nome de diretórios sem um barra na frente săo interpretados como diretórios ou caminhos relativos.
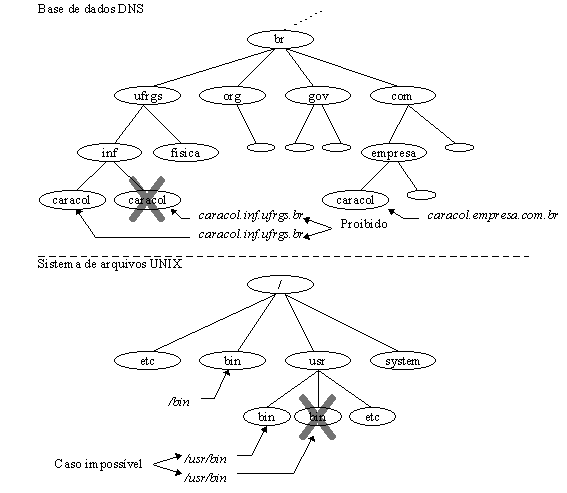
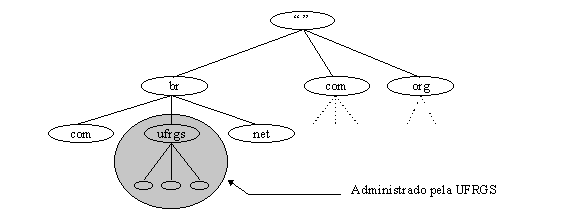
O DNS precisa que nodos irmăos, ou seja, nodos filhos do mesmo pai, tenham nomes únicos entre eles. Esta restriçăo garante que um nome de domínio seja identificado unicamente com um único nodo na árvore. A restriçăo, realmente, năo é uma limitaçăo desde que nomes precisam ser únicos somente entre os irmăos ou filhos de um mesmo pai, e năo entre todos os nodos da árvore. A mesma restriçăo aplica-se ao sistema de arquivos UNIX, vocę năo pode ter dois nodos irmăos com um mesmo nome. Assim como năo podem existir dois diretórios /usr/bin, também năo podem existir dois nodos caracol.inf.ufrgs.br no espaço de nomes (figura 3.2). Entretanto, podem existir um nodo caracol.inf.ufrgs.br e outro caracol.empresa.com.br, e da mesma forma, existir um diretório /bin e outro /usr/bin.
3.1.2 Domínios
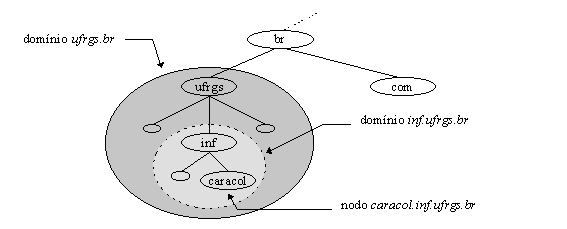
Um domínio é simplesmente uma sub-árvore de um espaço de nome de domínio. O nome de um domínio é o mesmo nome de domínio do nodo raiz da sub-árvore. Isto somente significa que o nome de um domínio é o nome do nodo do topo do domínio. Entăo, por exemplo, o topo do domínio "ufrgs.br" é o nodo chamado "ufrgs.br", como mostrado na figura 3.3.

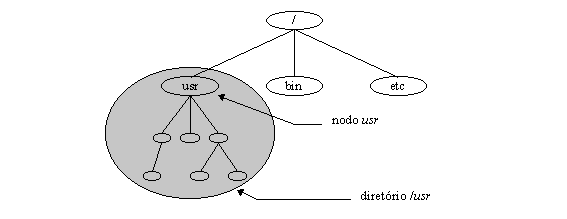
Da mesma forma, em um sistema de arquivos, no topo do diretório "/usr" vocę encontra um nodo chamado "/usr", como mostra a figura 3.4.
Cada nome de domínio na sub-árvore é considerado uma parte de um domínio. Partindo da idéia de que um nome de domínio pode estar em muitas sub-árvores, entăo conclui-se que um nome de domínio pode estar, também, em muitos domínios. Por exemplo, o nome de domínio caracol.inf.ufrgs.br é parte do domínio inf.ufrgs.br, e também parte do domínio ufrgs.br, como mostra a figura 3.5.
Entăo, resumindo-se, um domínio é somente uma sub-árvore de um espaço de nomes de domínio. Entretanto, se um domínio é formado somente de nomes de domínio e outros domínios, onde estăo todos os hosts? Bem, domínios săo grupos de máquinas.
As máquinas estăo lá, mas elas săo domínios também. E lembre-se, nomes de domínio săo somente índices dentro da base de dados do DNS. Os "hosts" no DNS săo os nomes de domínio que apontam para informaçőes sobre computadores individuais. E um domínio contęm todas as máquinas as quais seus nomes de domínios estăo dentro deste domínio. Os computadores săo agrupados de forma lógica, freqüentemente por regiőes ou por organizaçőes, e năo necessariamente por rede, ou endereço ou tipo de hardware. Vocę pode ter dez máquinas diferentes, cada uma delas em uma rede diferente, e talvez cada uma delas em um pais diferente, todos no mesmo domínio.
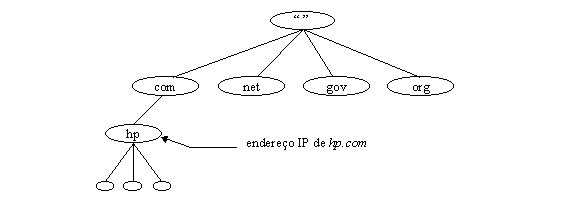
Os domínios que săo as folhas da árvore geralmente representam máquinas individuais. Seus nomes de domínios podem apontar para endereços de rede, informaçőes de hardware e informaçőes de roteamento de mail. Nomes de domínio no interior da árvore podem ser um computador e podem apontar para informaçőes estruturais sobre os filhos do domínio, ou seja, seus sub-domínios. Nomes de domínio interiores năo estăo restritos a um ou ao outro caso. Podem representar tanto o domínio que eles representam ou uma máquina particular na rede. Por exemplo, "hp.com" é o nome do domínio da companhia Hewlett-Packard e também o nome de domínio do computador que distribui o mail entre a HP e a Internet.
O tipo de informaçăo (estrutural ou sobre uma máquina) devolvido em uma pergunta ao servidor dnsl, depende do contexto do qual o nome de domínio está sendo usado. Em uma procura pelos filhos de um nodo pode retornar dados estruturais, ao passo que se fizer um telnet para o nome de domínio, a informaçăo retornada é sobre o host ao qual se deseja conectar (por exemplo, o endereço IP de "hp.com", mostrado na figura 3.6).
Um modo simples de se descobrir, se um domínio é um sub-domínio de um outro, pode ser comparar os seus nomes de domínio. Um nome de sub-domínio termina com nome de seu domínio pai. Por exemplo, o domínio inf.ufrgs.br deve ser um sub-domínio de ufrgs.br, uma vez que inf.ufrgs.br termina com ufrgs.br. Da mesma forma, é um sub-domínio de br, assim como também é ufrgs.br.
Além de ser relacionado em termos relativos, como sub-domínios de outros domínios, estes săo atribuídos por níveis. Nas listas de mail e nos "newsgroups" da USENET, vocę pode ver os termos nível do topo (em inglęs, top-level) ou segundo nível. Isto somente se aplica ŕ posiçăo do domínio dentro do espaço de nomes de domínio:
Os dados associados com os nomes de domínio ficam armazenados em registros de recursos (em inglęs, resource records), ou RR para abreviar. Os registros săo divididos por classes. Cada classe de registro pertence a um tipo de rede ou software. Atualmente, existem classes para internets (qualquer internet baseada em TCP/IP), redes baseadas nos protocolos Chaosnet, e redes que usam o software Hesiod. (Chaosnet é uma antiga rede de grande importância histórica.)
A classe da internet é de longe a mais popular de todas. (Realmente năo se sabe ao certo se alguém ainda usa a classe Chaosnet, e o uso da classe Hesiod é principalmente restrito ao MIT.) Neste trabalho, todo esforço será concentrado na classe internet, por ser a mais difundida e usada de todas.
Os registros podem ser de diferentes tipos, que correspondem as diferentes variedades de dados que podem ser armazenadas no espaço de nome de domínio. Diferentes classes podem definir diferentes tipos de registros, ainda que possam existir alguns tipos em comum para mais de uma classe. Por exemplo, quase todas classes definem um tipo para endereço. Cada tipo de registro define uma sintaxe particular de registro, que todos registros de recursos daquele tipo devem seguir.
3.2 O Espaço de Nomes de Domínio da Internet
O Sistema de Nomes de Domínio năo impőe muitas regras para os nomes de domínio, e năo associa nenhum significado particular para os nomes em nenhum nível. Quando se administra uma parte do espaço de nomes de domínio, vocę pode decidir na sua própria semântica para seus nomes de domínio. Entăo, vocę pode nomear seus sub-domínios de A até Z e ninguém poderá parar vocę (embora eles poderăo recomendar fortemente que năo o faça).
O espaço de nomes de domínio da Internet existente, entretanto, tem alguma estrutura imposta para ele mesmo. Especialmente nos domínios de níveis superiores, os nomes de domínio seguem certas tradiçőes (e năo regras, uma vez que eles podem e tęm quebrado). Săo essas tradiçőes que ajudam os nomes de domínios năo parecerem tăo caóticos. Entender elas é um grande passo se vocę está tentando decifrar um nome de domínio.
3.2.1 Domínios Top-level (primeiro nível)
Os domínios de primeiro nível originais dividiram o espaço de nomes de domínio da Internet por tipos de organizaçőes. Como inicialmente a Internet estava restrita aos Estados Unidos (seus fundadores), esta divisăo era praticada para as organizaçőes norte-americanas. Aqui estăo os sete principais domínios top-level:
Existe ainda um domínio de primeiro nível chamado arpa, que originalmente era usado durante a transiçăo das tabelas de hosts (o arquivo HOSTS.TXT) para o DNS, na ARPANET. Todos as máquinas tinham os seus nomes originalmente sob o domínio arpa, onde eram facilmente encontrados. Depois, eles foram movidos para vários sub-domínios dos domínios organizacionais de primeiro nível.
Pode-se notar um certo preconceito nacionalista nos exemplos acima: todos citados săo organizaçőes primariamente norte-americanas. E isto é fácil de entender, quando se recorda que a Internet começou com a ARPANET, um projeto de pesquisa fundado pelos Estados Unidos. Ninguém poderia prever o sucesso da ARPANET, ou que ela poderia tornar-se um dia, uma rede internacional como atualmente é a Internet.
Para acomodar a internacionalizaçăo da Internet, os mentores do seu espaço de nomes entraram num acordo fazendo concessőes. Em vez de insistir que todos os domínios de primeiro nível descrevessem afiliaçőes organizacionais, eles decidiram permitir também, designaçőes geográficas. Os novos domínios top-level ficaram reservados (mas năo necessariamente criados) para corresponder individualmente a cada país. Seus nomes de domínio seguiram um padrăo internacional já existente, a norma ISO 3166. Esta norma estabelecia abreviaturas oficiais, de duas letras, para cada país no mundo. Esta lista está incluída no Apęndice A deste trabalho.
Dentro desses domínios de primeiro nível, as tradiçőes e algumas extensőes suas que săo seguidas variam. Alguns dos domínios de primeiro nível da ISO 3166 seguem o esquema original organizacional de perto. Por exemplo, o domínio do Brasil, br, tem sub-domínios com.br, para domínios comerciais, gov.br para organizaçőes governamentais, etc. A única exceçăo no Brasil fica para as universidades, primeiras entidades brasileiras a entrar na Internet, que estăo diretamente sob o domínio br, por exemplo ufrgs.br. Outro exemplo; o domínio da Austrália, au, segue o padrăo original, com sub-domínios como edu.au e com.au.
Alguns outros domínios top-level da ISO 3166 seguem o mesmo caminho do Reino Unido, uk, e tęm sub-domínios como co.uk para corporaçőes, e ac.uk para a comunidade acadęmica. Entretanto, na maioria do casos, mesmo esses domínios geográficos estăo subdivididos de maneira organizacional.
Mas isso năo é verdade para o domínio us dos Estados Unidos. O domínio us tem cinqüenta sub-domínios que correspondem aos cinqüenta estados norte-americanos. Cada um recebe o seu nome de domínio de acordo com o padrăo de abreviatura de duas letras para o estado (a mesma abreviatura padronizada pelo serviço postal dos Estados Unidos). Dentro do domínio de cada estado, a organizaçăo ainda é geográfica: a maioria dos sub-domínios correspondem a cidades individualmente. Abaixo das cidades, entăo, os sub-domínios correspondem aos computadores.
Agora que já se sabe o que representam a maioria dos domínios de primeiro nível e como seus espaços de nomes săo estruturados, será muito mais fácil entender os nomes de domínio. Por exemplo:
caracol.inf.ufrgs.br
Para entender-se esse nome de domínio deve-se lembrar que ufrgs.br é o domínio da Universidade Federal do Rio Grande do Sul (UFRGS), universidade localizada no Brasil (domínio br). Caso năo se recorde disso, pode-se tentar adivinhar que o domínio pertence a uma organizaçăo brasileira, e das primeiras a ligar-se na Internet (provavelmente uma universidade), pois năo tem nenhum outro domínio que especifique o tipo de organizaçăo. O sub-domínio inf indica o departamento de informática, e finalmente, caracol é o nome do host ligado ŕ rede.
arvoredo.interop.com.br
Bem, neste exemplo podemos verificar que este nome de domínio pertence a uma organizaçăo comercial, uma empresa brasileira chamada InterOp. Descobrimos isto simplesmente vendo-se os seus domínios pais, com.br, que sugerem ser uma entidade comercial (sub-domínio com) brasileira (domínio br). E finalmente arvoredo é um host dentro do domínio da empresa acima nominada.
beethoven.telesc.gov.br
Neste caso acima, pode-se deduzir que provavelmente este nome de domínio seja de uma empresa do governo brasileiro (gov.br), a TELESC, empresa de telecomunicaçőes do estado de Santa Catarina. E mais uma vez o nome mais abaixo deste domínio especifica um computador.
fernwood.mpk.ca.us
Aqui precisa-se entender o domínio us. O sub-domínio ca.us pertence ao estado da Califórnia, Estados Unidos, mas mpk dificilmente poderia-se descobrir que é o domínio de Menlo Park, sem conhecer-se a geografia da Baía de Săo Francisco.
3.4 A Distribuiçăo de Domínios
É sempre bom lembrar que um dos principais objetivos no planejamento do DNS foi a administraçăo descentralizada. E isto é alcançado delegando-se. Delegar-se domínios assemelha-se bastante com delegar-se tarefas. Um gerente pode dividir um grande projeto em tarefas menores e delegar a responsabilidade de cada uma das tarefas para diferentes empregados.
Desta forma, uma organizaçăo administrando um domínio pode dividi-lo em sub-domínios. Cada um desses sub-domínios pode ser delegado, inclusive, a outras organizaçőes. Isto significa que a organizaçăo para a qual é delegada um domínio fica responsável por manter toda a informaçăo naquele sub-domínio. Ela pode livremente mudar os dados, e pode até dividir seu sub-domínio em outros e delegá-los a outras organizaçőes. O domínio pai contém somente ponteiros para as fontes de informaçőes do sub-domínio, para que possa encaminhar as perguntas a elas. Por exemplo, o domínio ufrgs.br é delegado ao pessoal da UFRGS que gerencia a rede da universidade (figura 3.7).
Nem todas as organizaçőes delegam seus domínios inteiros, assim como nem todos gerentes delegam todo o seu trabalho. Em um domínio podem haver vários sub-domínios, e também, conter máquinas que năo estăo em nenhum sub-domínio. Em um exemplo fictício (retirado de um livro), a Acme Corporation, que possui uma divisăo em Rockaway e seus escritórios centrais em Kalamazoo, pode ter os sub-domínios rockaway.acme.com e kalamazoo.acme.com. Entretanto, alguns poucos hosts nos escritórios de vendas da Acme, espalhados pelos Estados Unidos, ficariam melhor diretamente abaixo de acme.com.
Desta forma, é importante que entenda-se o conceito do termo delegar, que se refere a atribuir a responsabilidade de um sub-domínio a uma outra organizaçăo.
Os programas que armazenam as informaçőes sobre o espaço de nomes de domínio săo chamados de servidores de nomes (em inglęs, name server). Servidores de nomes geralmente tęm informaçőes completas sobre alguma parte do espaço de nomes de domínio, chamada de zona. Servidores de nomes podem ter autoridade por mais de uma zona, também.
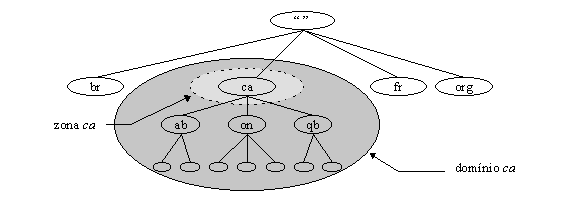
A diferença entre uma zona e um domínio é tęnue. Uma zona contém os nomes de domínio e os dados que um domínio contém, exceto pelos nomes de domínio e as informaçőes que săo delegados para outras zonas. Por exemplo, o domínio de primeiro nível ca (de Canadá) pode ter os sub-domínios ab.ca, on.ca, e qb.ca, para as províncias de Alberta, Ontario e Quebec, respectivamente. A autoridade para os domínios ab.ca, on.ca e qb.ca pode ser delegada para organizaçőes em cada uma das províncias. O domínio ca contém todos os dados em ca mais todos os dados em ab.ca, on.ca e qb.ca. Mas a zona ca somente contém os dados em ca (figura 3.8).
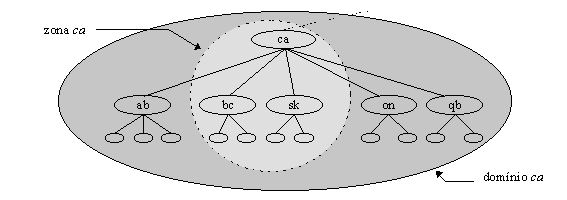
Entretanto, se um sub-domínio năo é delegado para outrem, a zona do domínio pai contém os nomes de domínio e dados do sub-domínio. Entăo, os sub-domínios bc.ca e sk.ca (British Columbia e Saskatchewan) do domínio ca podem existir, mas năo serem delegados a ninguém. Neste caso, a zona ca contém dados de mais de um nível, contendo bc.ca e sk.ca, mas năo outros sub-domínios de ca, como mostra a figura 3.9.
Entăo, por quę servidores de nomes carregam zonas em vez de domínios? Porque um domínio pode conter mais informaçőes que um servidor de nomes pode precisar: ele poderia conter dados delegados a outros servidores de nomes, o que é desnecessário.
No caso de um domínio recém criado, ele provavelmente năo terá nenhum sub-domínio. Desta forma, como năo há nada delegado a ninguém, o domínio e a sua zona conterăo os mesmos dados.
O ato de delegar, resumindo-se, é a atribuiçăo da responsabilidade por alguma parte do seu domínio para outra organizaçăo. O que realmente acontece, entăo, é a atribuiçăo da autoridade sobre seus sub-domínios para diferentes servidores de nomes.
Os seus dados, em vez de conterem informaçőes sobre os sub-domínios que foram delegados, incluem ponteiros para os servidores de nomes que tęm autoridade sobre os seus sub-domínios. Desta forma, se um dos seus servidores de nomes é perguntado sobre dados de algum de seus sub-domínios delegados, ele pode responder com uma lista dos servidores de nomes com os quais se pode conseguir maiores informaçőes.
3.5.2 Tipos de Servidores de Nomes
As especificaçőes do DNS definem dois tipos de servidores de nomes: primary master (controlador primário) e secondary master (controlador secundário). Um servidor de nomes primário pega os dados para as zonas que tem autoridade a partir de arquivos na máquina em que está rodando. Um servidor de nomes secundário pega os dados da sua zona de outro servidor de nomes que tenha autoridade para a zona. Quando um servidor secundário começa a rodar, ele contacta o servidor de nomes do qual ele deve pegar as informaçőes e, se necessário, busca os dados da zona. Isto é chamado de zone transfer (transferęncia na zona).
O DNS provę estes dois tipos de servidores de nomes para facilitar a administraçăo. Uma vez criados os dados para um zona, e configurado um servidor de nomes primário, năo é mais necessário perder-se tempo copiando-se os dados de máquina para máquina a fim de criarem-se mais servidores de nomes para a zona. Simplesmente configuram-se os servidores de nomes secundários para carregarem os dados a partir do servidor primário. Uma vez configurados, os secundários irăo periodicamente contactar o primário para verificarem se estăo atualizados, e se necessário, buscarem novamente os dados.
Isto é importante porque é uma grande idéia ter-se mais de um servidor de nomes para qualquer zona. As vantagens săo a redundância dos dados, a distribuiçăo da carga da rede, e para ter-se certeza que todas as máquinas tem um servidor de nomes por perto. Usar servidores de nomes secundários torna a administraçăo mais prática.
Chamar um servidor de nomes de servidor primário ou secundário é, entretanto, um pouco complicado. Um servidor de nomes pode ter autoridade sobre mais de uma zona. Da mesma forma, um servidor de nomes pode ser um controlador primário para uma zona, e controlador secundário para outra. Todavia, a maioria dos servidores de nomes săo, ou primários para a maioria das zonas que carregam, ou secundários para a maioria de suas zonas. Entăo, chamando-se um servidor de nomes em particular de primário ou secundário, significa que ele é controlador primário ou secundário para a maiorias das zonas que ele carrega.
Os arquivos de onde os servidores de nomes primários carregam os dados de suas zonas săo chamados, simplesmente, de arquivos de dados ou arquivos das zonas. Geralmente referem-se a eles como db files, abreviatura em inglęs para arquivos da base de dados. Os servidores de nomes secundários algumas vezes também carregam os dados da zona a partir arquivos locais. Freqüentemente os servidores secundários săo configurados para armazenar cópias de segurança, em arquivos, dos dados que eles buscaram em um servidor de nomes primário. Se a execuçăo de um servidor secundário é terminada e reiniciada, ele irá, primeiramente, ler as suas cópias de segurança, e entăo conferir se elas estăo atualizadas. Isto elimina a necessidade de transferir todos os dados da zona no caso de eles năo terem mudado, e provę um fonte de dados no caso do servidor primário estar parado.
Os arquivos de dados contém registros de recursos que descrevem a zona. Os registros de recursos descrevem todas as máquinas na zona, e marcam qualquer sub-domínios que estejam delegados. O BIND também permite diretivas especiais para incluir os conteúdos de outros arquivos em arquivo de dados, muitos parecidos com a declaraçăo #include da programaçăo em linguagem C.
Os resolvers (ou resolvedores) săo os clientes que acessam os servidores de nomes. Os programas rodando em um computador que necessita informaçőes do espaço de nomes de domínio usam o resolver. O resolver trata de:
No BIND, o resolver é somente um conjunto de funçőes de uma biblioteca que ficam compiladas dentro de programas como o telnet e o ftp. Eles năo săo nem processos separados. Eles săo espertos o suficiente para enviar a pergunta, aguardar a resposta, e reenviá-la caso năo seja respondida. Mas é só isso. A maior parte do trabalho de achar uma resposta para uma pesquisa fica com o servidor de nomes. As especificaçőes do DNS chamam esse tipo usado no BIND de stub resolver (resolvedor curto, ou burro).
Outras implementaçőes do DNS tęm resolvers mais inteligentes, que podem fazer tarefas mais sofisticadas, como construir uma cache das informaçőes já buscadas dos servidores de nomes. Contudo, estas implementaçőes năo săo comuns como o stub resolver do BIND.
Os servidores de nomes săo profundos conhecedores da arte de buscar informaçőes do espaço de nomes de domínio. Eles devem ser, dada a limitada inteligęncia de alguns resolvedores. Eles podem ,năo somente, responder dados sobre zonas que eles tęm autoridade, mas também podem pesquisar o espaço de nomes de domínio para achar dados que eles năo tęm autoridade. Este processo é chamado de resoluçăo de nomes (em inglęs, name resolution ou simplesmente resolution).
Por causa da estrutura do espaço de nomes ser uma árvore invertida, um servidor de nomes somente precisa de uma peça de informaçăo para encontrar o caminho até qualquer ponto da árvore: os nomes e endereços dos servidores de nomes da raiz. Um servidor de nomes pode enviar uma pergunta para um servidor da raiz, pedindo dados sobre qualquer nome no espaço de nomes de domínio, e o servidor raiz irá indicar a quem perguntou sobre o caminho que deve começar a procurar.
3.7.1 Servidores de Nomes da Raiz
Os servidores de nomes da raiz sabem onde estăo os servidores com autoridade sobre todos os domínio de primeiro nível (top-level). Recebida um pergunta sobre qualquer nome de domínio, os servidores de nomes da raiz podem pelo menos responder os nomes e endereços dos servidores com autoridade sobre o domínio de primeiro nível, ao qual o nome de domínio pertence. E estes servidores de primeiro nível podem prover a lista dos servidores de nomes com autoridade sobre o domínio de segundo nível, no qual o nome de domínio está dentro. Cada servidor de nomes pesquisado responde com a informaçăo sobre como chegar-se mais "perto" da resposta procurada, ou provę a própria resposta.
Os servidores de nomes da raiz săo um elo chave na resoluçăo de nomes. Desta forma, sendo tăo importantes, o DNS provę mecanismos (como cache, que serăo discutidos mais adiante) para ajudar a descarregar os servidores de nomes da raiz. Porém, na ausęncia de outra informaçăo, a resoluçăo deve começar nos servidores da raiz. Isto torna os servidores de nomes da raiz cruciais para a operaçăo do DNS; se todos os servidores de nomes raiz da Internet tornarem-se inalcançáveis por um período longo, toda resoluçăo de nomes na Internet irá falhar. Por este motivo, a Internet tem nove servidores de nomes da raiz (quando este trabalho foi terminado), espalhados por diferentes partes da rede. Alguns estăo na MILNET, a porçăo militar dos Estados Unidos da Internet; outro na SPAN, internet da NASA; um está na Europa; e um é mantido por um provedor de acesso comercial ŕ Internet.
Sendo alvo de tantas pesquisas deixam os servidores raiz muito ocupados; mesmo com muitos servidores, o tráfego para cada servidor de nomes da raiz é muito alto. Um estudo feito em 1992 pela U.S.C. dos Estados Unidos concluiu que o seu servidor da raiz recebia aproximadamente 20.000 pacotes com perguntas em uma hora, ou praticamente 6 perguntas por segundo. Estatísticas mais recentes feitas pelo InterNIC mostram que o seu servidor de nomes da raiz, ns.internet.net, recebe 255.600 perguntas por hora, ou quase 71 perguntas por segundo.
Apesar da alta carga dos servidores da raiz, a resoluçăo de nomes na Internet funciona muito bem. A figura 3.10 mostra o processo de resoluçăo para o endereço de uma máquina real em um domínio real, incluindo como o processo atravessa a árvore do espaço de nomes de domínio.
O servidor de nomes local pergunta a um servidor da raiz pelo endereço de beethoven.telesc.gov.br e recebe indicaçăo para os servidores de nomes de br. Ele faz a mesma pergunta a um servidor de nomes de br, e é indicado para os servidores de nomes de gov.br. Os servidores de nomes de gov.br referenciam o servidor de nomes do domínio telesc.gov.br. Finalmente, o servidor de nomes local pergunta ao servidor de telesc.gov.br pelo endereço, e entăo, recebe a resposta desejada.
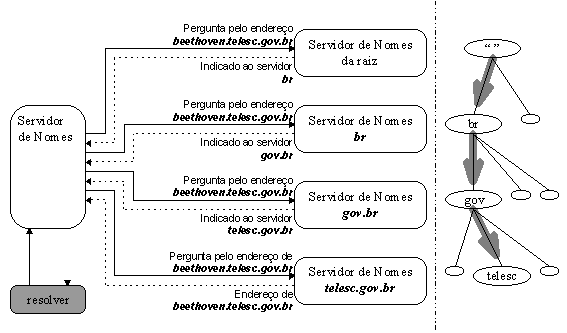
Pode-se notar uma grande diferença na quantidade de trabalho feito pelos servidores de nomes, neste último exemplo. Quatro dos servidores simplesmente retornaram a melhor resposta que eles tinham (a maioria indicava outros servidores de nomes) para as perguntas recebidas. Eles năo precisaram enviar suas próprias perguntas para achar os dados requisitados. Contudo um servidor de nomes, aquele pesquisado pelo resolver, teve que seguir sucessivas indicaçőes até receber a resposta final.
E por que ele năo poderia simplesmente indicar ao resolvedor outro servidor? Porque um stub resolver năo tem a inteligęncia necessária para seguir um referęncia. E como um servidor de nomes sabe que năo deve responder com uma indicaçăo? Basta o resolver enviar uma pergunta recursiva.
As perguntas podem ser de dois tipos: recursivas e interativas (ou năo-recursivas). Perguntas recursivas localizam a maior parte do trabalho de resoluçăo em só um servidor de nomes. Recursăo, ou resoluçăo recursiva, é somente um nome para o processo de resoluçăo usado por um servidor de nomes quando ele recebe perguntas recursivas.
Interaçăo ou resoluçăo interativa, de outro lado, refere-se ao processo de resoluçăo usado por um servidor de nomes quando recebe perguntas interativas.
Na recursăo, um resolver envia uma pergunta a um servidor de nomes por informaçőes sobre um nome de domínio em particular. O servidor de nomes perguntado é entăo forçado a responder com o dado requisitado, ou com um erro especificando que o dado do tipo pedido năo existe ou que o nome de domínio especificado năo existe. O servidor de nomes năo pode somente indicar a quem perguntou para um servidor de nomes diferente, porque a pergunta era recursiva.
Se o servidor de nomes pesquisado năo tiver autoridade sobre os dados requisitados, ele terá que perguntar a outro servidor para encontrar a resposta. Ele pode enviar perguntas recursivas aos outros servidores de nomes, desta forma obrigando-os a encontrar uma resposta e devolve-la (passando o problema adiante). Ou entăo enviar perguntas interativas, e possivelmente ser indicado para outros servidores de nomes que estejam "mais perto" do nome de domínio que se está procurando. As implementaçőes atuais săo geralmente mais "educadas" e fazem o último caso, seguindo as indicaçőes até que uma resposta seja encontrada.
A resoluçăo interativa, de outra forma, năo exige muito trabalho da parte do servidor de nomes perguntado. Na resoluçăo interativa, o servidor de nomes simplesmente fornece a melhor resposta que ele já sabe a quem perguntou-lhe. Năo é necessário que ele saia perguntando mais. O servidor perguntado consulta seus dados locais (incluindo a sua cache, que será explicado mais adiante), procurando pela informaçăo requisitada. Se ele năo encontra o dado ali, ele faz a melhor tentativa para dar a quem perguntou uma informaçăo que auxilie a continuar no processo de resoluçăo. Geralmente essas săo os nomes e endereços dos servidores de nomes "mais perto" do dado que se está procurando.
O que isto importa para o processo de resoluçăo pode-se observar por completo na figura 3.11.
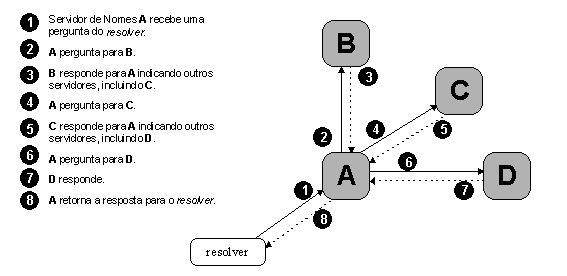
Um resolver pergunta a um servidor de nomes local, que entăo pergunta a vários outros servidores de nomes no intuito de responder ao resolver. Cada servidor que o servidor local pergunta referencia a outro servidor de nomes com autoridade sobre uma zona cada vez mais abaixo no espaço de nomes e mais perto da resposta final. Finalmente o servidor de nomes local pergunta ao servidor com autoridade sobre o nome de domínio perguntado, que devolve uma resposta.
3.7.4 Mapeando Endereços para Nomes
Uma parte importante da funcionalidade do processo de resoluçăo de nomes ainda está faltando: como endereços săo mapeados de volta para nomes. O mapeamento endereçoZ nome é usado para produzir uma saída mais fácil para os humanos lerem e interpretarem (em arquivos de log, por exemplo). Também é usado em algumas conferęncias de autorizaçőes. Máquinas UNIX mapeiam endereços para nomes de máquinas com o intuito de comparar com as suas entradas dos arquivos .rhosts e hosts.equiv, por exemplo. Quando se usa tabelas de hosts (host tables), o mapeamento endereçoZ nome é trivial. Executa-se uma busca seqüencial pelo endereço, procurando-se em todo o arquivo de hosts. A procura retorna o nome oficial da máquina listado. No DNS, entretanto, o mapeamento endereçoZ nome năo é tăo simples. Os dados, incluindo endereços, no sistema de nomes de domínio săo indexados por nome. Encontrar um endereço dado um nome de domínio é relativamente fácil. Todavia, encontrar um nome de domínio que corresponda a um dado endereço iria requerer uma busca exaustiva em todos os nomes de domínio da árvore.
Na verdade, existe uma soluçăo melhor que é ao mesmo tempo simples e efetiva. Considerando-se que é fácil encontrar dados quando tęm-se o nome, que serve de índice, por que năo criar uma parte do espaço de nomes de domínio que use endereços como nomes? No espaço de nomes de domínio da Internet, esta porçăo do espaço de nomes é o domínio in-addr.arpa.
Os nodos no domínio in-addr.arpa săo nomeados atrás dos números na representaçăo dotted-octet (octetos-pontuados) de endereços IP. (A representaçăo dotted-octet é o método mais comum de expressar os endereços IP de 32 bits como números de 0 a 255, separados por pontos.) O domínio in-addr.arpa, por exemplo, pode ter até 256 sub-domínios, cada um correspondendo a um possível valor no primeiro octeto de um endereço IP. Cada um destes sub-domínios pode ter mais 256 sub-domínios para si, correspondendo aos possíveis valores do segundo byte. Finalmente, no quarto nível abaixo, existirăo registros de recursos associados ao octeto final dando o nome de domínio completo da máquina ou rede daquele endereço IP. Isto torna in-addr.arpa um domínio incrivelmente grande, mostrado em parte na figura 3.12, e suficiente para cada endereço IP na Internet.
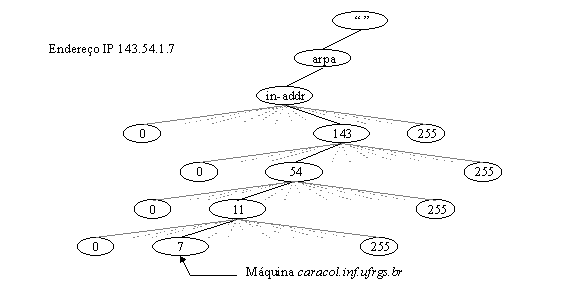
Pode-se notar que quando se lę como um nome de domínio, o endereço IP aparece invertido, ou seja, de trás para frente, de forma que o nome é lido da folha até a raiz da árvore. Por exemplo, se caracol.inf.ufrgs.br tem o endereço IP 143.54.11.7, o sub-domínio in-addr.arpa correspondente é 7.11.54.143.in-addr.arpa, que mapeia de volta para o nome de domínio caracol.inf.ufrgs.br.
Os endereços IP poderiam serem representados da maneira oposta no espaço de nomes, com o primeiro octeto do endereço IP mais abaixo do domínio in-addr.arpa. Desta forma, o endereço IP seria lido corretamente no nome de domínio.
Entretanto, endereços IP săo hierárquicos, assim como nomes de domínio. Números de rede săo distribuídos assim como nomes de domínio, e os administradores podem dividir os seus endereços de rede e delegar as sub-redes. A diferença é que endereços IP ficam mais específicos da esquerda para a direita, enquanto nomes de domínio ficam menos específicos da esquerda para a direita. A figura 3.13 exemplifica melhor isto.
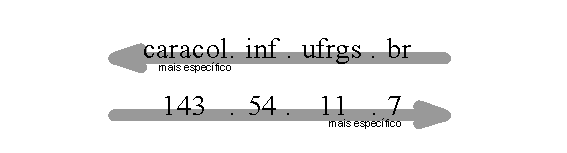
Fazendo-se os primeiros bytes no endereço IP aparecerem mais acima na árvore possibilita aos administradores a habilidade de delegar a autoridade para os sub-domínios in-addr.arpa juntamente com os seus endereços de rede. Por exemplo, o domínio 54.143.in-addr.arpa, que contém as informaçőes de mapeamento reverso para todos os hosts que possuem endereços IP que comecem com 143.54, pode ser delegado para os administradores da rede 143.54.0.0. Isto seria impossível se os octetos ficassem na ordem inversa. Se os endereços IP fossem representados da outra forma, o domínio 54.143.in-addr.arpa consistiria de todos as máquinas que tivessem um endereço IP terminado com 54.143 (năo um domínio prático de delegar-se).
O espaço de nomes in-addr.arpa, entretanto, somente pode ser usado para o mapeamento endereço IPŕ nome de domínio. A procura por um nome de domínio que é indexado por um tipo de dado arbitrário (algo além de um endereço), no espaço de nomes de domínio requeriria um outro espaço de nomes especializado como o in-addr.arpa, ou uma busca exaustiva.
Esta procura exaustiva é possível, até certo grau. Uma busca invertida (inverse query, em inglęs) é uma procura por um nome de domínio que é indexado por um determinado dado. Ela é processada somente pelo servidor de nomes que recebeu a pergunta. Este servidor de nomes procura em todos os seus dados locais pelo item procurado e retorna o nome de domínio correspondente, se possível. Caso ele năo encontre o dado, ele desiste. Nenhuma tentativa é feita para repassar a busca para outro servidor de nomes.
Uma vez que qualquer servidor de nomes somente possui dados de parte de todo o espaço de nomes de domínio, uma busca invertida nunca tem garantia de retornar uma resposta. Por exemplo, se um servidor de nomes recebe uma busca invertida por um endereço IP que ele năo sabe nada a respeito, ele năo pode retornar uma resposta, mas também năo sabe se o endereço IP existe ou năo, uma vez que somente possui parte da base de dados do DNS. E ainda tem mais, a implementaçăo de busca invertidas é opcional dependendo da especificaçăo de DNS. O BIND 4.9.4 ainda possui o código que implementa buscas invertidas, embora esteja comentado.
Todo o processo de resoluçăo parece horrivelmente confuso e enfadonho para quem está acostumado a simples buscas através da tabela de hosts. Realmente, o uso das hosts tables é usualmente um processo muito rápido. E uma das características que aumenta consideravelmente a velocidade é manter-se uma cache (memória temporária).
Um servidor de nomes processando uma pesquisa recursiva poderá ter que enviar algumas outras perguntas para encontrar uma resposta. Contudo, ele descobre bastante informaçăo sobre o espaço de nomes de domínio enquanto procura. Cada vez que ele recebe uma outra lista de servidores de nomes, ele aprende que aqueles servidores tęm autoridade sobre determinada zona, e aprende os endereços desses servidores. E, ao final do processo de resoluçăo, quando ele finalmente encontra o dado procurado originalmente, pode armazenar o dado para uso futuro. Com a versăo 4.9.3 do BIND, os servidores de nomes também implementam negative caching: se um servidor de nomes com autoridade responde a uma pergunta com uma resposta, afirmando que o tipo de informaçăo procurada năo existe, para o nome de domínio especificado, o servidor de nomes local irá armazenar temporariamente na cache esta informaçăo. Os servidores de nomes guardam na cache todos esses dados para ajudar a agilizar pesquisas sucessivas. Assim, a próxima vez que um resolver perguntar ao servidor de nomes por um dado, sobre um nome de domínio que o servidor já saiba algo, o processo é encurtado um pouco. O servidor de nomes poderia ter a resposta na cache, positiva ou negativamente. Neste caso ele simplesmente retorna a resposta para o resolvedor. Mesmo que ele năo tenha a resposta na cache, ele poderia já ter "aprendido" as identidades dos servidores de nomes com autoridade sobre a zona na qual está o nome de domínio, e estar pronto para perguntá-los diretamente.
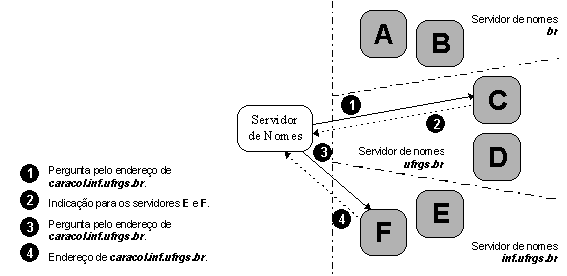
Por exemplo, caso um servidor de nomes (ns1) já tenha procurado pelo endereço de penta.ufrgs.br. No processo de procura, ele armazenaria na cache os nomes e endereços dos servidores de nomes de penta.ufrgs.br e ufrgs.br (mais o endereço IP de penta.ufrgs.br). Agora, se um resolver perguntasse ao servidor ns1 pelo endereço de caracol.inf.ufrgs.br, o ns1 iria pular a pergunta aos servidores de nomes da raiz. Reconhecendo que ufrgs.br é o antecessor mais perto de caracol.inf.ufrgs.br que ele conhece, o servidor de nomes ns1 iria começar a pesquisar no servidor de nomes de ufrgs.br, como mostra a figura 3.14. De outra forma, se o servidor de nomes ns1 tivesse encontrado que năo existia endereço para caracol.inf.ufrgs.br, a próxima vez que ele fosse perguntado pelo endereço, ele poderia simplesmente responder apropriadamente com a informaçăo da sua cache.
Além de aumentar a velocidade da resoluçăo de nomes, o uso de cache evita mais buscas aos servidores de nomes da raiz. Isto significa que os servidores năo săo mais tăo dependentes da raiz, e os servidores da raiz năo irăo sofrer muito com as perguntas de outros servidores.
Os servidores de nomes năo podem guardar os dados na cache para sempre, é claro, e por isso é também chamada de memória temporária. Se os servidores a guardassem para sempre, as mudanças dos dados nos servidores de dados com autoridade năo iriam nunca alcançar o resto da rede. Os servidores de nomes remotos iriam continuar somente a usar os dados da cache. Por este motivo, o administrador da zona que contém os dados decide um time to live (tempo de vida), ou TTL, para os dados. O time to live é a quantidade de tempo que qualquer servidor de nomes está permitido a armazenar na cache os dados. Depois de expirado o tempo de vida, o servidor de nomes deve descartar os dados da cache e buscar novos dados dos servidores de nomes com autoridade sobre a zona. Isto também se aplica aos dados armazenados negativamente na cache; o servidor de nomes deve desconsiderar uma resposta negativa após um período, também, para o caso de dados novos terem sido adicionados nos servidores de nomes com autoridade sobre a determinada zona. Todavia, o tempo de vida para dados negativos da cache năo pode ser selecionado pelo administrador do domínio; é fixo em dez minutos.
Os servidores de nomes năo podem guardar os dados na cache para sempre, é claro, e por isso é também chamada de memória temporária. Se os servidores a guardassem para sempre, as mudanças dos dados nos servidores de dados com autoridade năo iriam nunca alcançar o resto da rede. Os servidores de nomes remotos iriam continuar somente a usar os dados da cache. Por este motivo, o administrador da zona que contém os dados decide um time to live (tempo de vida), ou TTL, para os dados. O time to live é a quantidade de tempo que qualquer servidor de nomes está permitido a armazenar na cache os dados. Depois de expirado o tempo de vida, o servidor de nomes deve descartar os dados da cache e buscar novos dados dos servidores de nomes com autoridade sobre a zona. Isto também se aplica aos dados armazenados negativamente na cache; o servidor de nomes deve desconsiderar uma resposta negativa após um período, também, para o caso de dados novos terem sido adicionados nos servidores de nomes com autoridade sobre a determinada zona. Todavia, o tempo de vida para dados negativos da cache năo pode ser selecionado pelo administrador do domínio; é fixo em dez minutos.
Decidir um time to live para os seus dados é essencialmente decidir uma relaçăo entre performance e consistęncia. Um TTL pequeno irá ajudar a assegurar que os dados sobre o seu domínio fiquem consistentes através da rede, por que os servidores de nomes remotos irăo descartar os seus dados mais rapidamente, e serăo forçados a perguntar aos seus servidores de nomes com autoridade mais freqüentemente por novos dados. De outro modo, isto irá aumentar a carga de trabalho nos seus servidores e, conseqüentemente aumentar o tempo médio de resoluçăo por informaçőes no seu domínio.
Um TTL grande irá encurtar o tempo médio que leva para resolver-se informaçőes no seu domínio, uma vez que poderá ser armazenada por um longo tempo. Em contrapartida, as informaçőes sobre o seu domínio ficarăo inconsistentes por um período maior caso sejam feitas alteraçőes nos dados dos seus servidores de nomes.
Deste modo, o melhor é encontrar uma relaçăo ótima entre esses dois itens, baseando-se na carga média dos seus servidores e na freqüęncia das alteraçőes no seu domínio, resultando em um time to live ideal.
![]()
![]()