Gerenciando Redes ATM: Falhas e Gerenciamento de Configuração
Tutorial
{kind=link}
Gerenciando Redes ATM: Falhas e Gerenciamento de Configuração
Gerenciando Redes ATM: Falhas e Gerenciamento de Configuração
Tutorial
Gerenciando Redes ATM: Falhas e Gerenciamento de Configuração
Gerenciamento de falhas é fundamental e determinante
em redes confiáveis. Gerenciar e possuir ferramentas para resolver
e prever
problemas. Com gerenciamento é possível reconfigurar
Redes ATM rapidamente e fácilmente para encontrar câmbios
necessidades
e responder à emergências que possam estar num rango de
demanda pico em desastres físicos.
Gerenciamento de falhas
Usado para detectar e isolar problemas em redes ATM, a tabela
7.1 numera algumas das funções que podem ser suportadas de
acordo com as falhas de um nível geral, na tabela 7.2 especifica
à funcionalidade que tem sido proposta para switches ATM.
Como se pode ver na tabela 7.2, o gerenciamento de falhas e funções
pode ser agrupado dentro de dois categorias gerais: Funções
de vigilância de alarme, que inclui monitoramento de falhas e
capacidades de notificação de falhas, localizações
de falhas e testes de
funções, analises de circuitos e características
de equipamentos que possibilitam ou habilitam elementos na rede, tais como
switch,
condição interna própria para diagnostico.
| Permitir, impedir e mudar condiciões de reportes de alarmes.
e definir login de alarme. e reset audivles ou indicações de alarme visual. designação e requerimento de alarme de evento de criterio construir, editar, review, e cancelar reportes com problemas. recebir alarme de reportes . Recebir e reações e notificações de deteção de errors testes de resultados de reportes. Rectificação de falhas de sistemas de comunicações Requerimentos e recibemento de localizações de diagnosticos de reportes de falhas Requerimentos, recibemento e esquemas sumários de reportes de falhas Conjunto de acessos de testes |
Vigilância de Alarme
As funções de vigilância de alarme são
designadas para detecção e notificação de falhas
na rede. Para switch ATM, mediante estas
funções são desempenhadas em condições
básicas dentro de características NEs de gerenciamento de
sistemas. Vigilância de alarme
é preocupação de monitoramento de anomalias, defeitos
e falhas.
As anomalias é a primeira indicação de problemas
na rede. Se a ocorrência desta anomalia e por um período
curto (usualmente em fração
de segundo), um defeito e declarado. Os elementos da rede notificam
a outros elementos de redes usando alarmes tais como sinal de indicação
de alarme (AIs). Ações automáticas são
inicializadas dentro dos elementos de redes para corrigir problemas.
Se o defeito persiste
(em poucos segundos)uma falhas é declarada e o sistema de gerenciamento
apropriado é notificado.
Na tabela 7.2 estão as três majores aspectos de processos
vigilantes de alarmes. O primeiro envolve a detecção
de falhas na camada física e
camada ATM respectivamente, e a declaração de defeito
de inband indicações de alarme tais como Ais e indicações
de defeitos remotos
(RDIs)entre NEs afeitados por defeitos. O terceiro aspecto de
vigilância de alarme envolve reportes de falhas.
| Vigilância de Alarme | Defeito da camada física e deteção de falhas com
gerenciamento de sinais de inband.
Vigilância de alarme para ATM sobre DSn Deteção de falha quando camada física de protocolo de convergencia é usado. Os defeitos e falhas da camada fisica de ATM são gerenciamento com sinais de alarmes (VP e VC) As sinais de indicação de alarme (AIS)/indicador de defeito remoto (RDI) verficam continuamente a capacidade. |
| Reporte de falhas | Reporte de falha quando a falha é detectada localmente
Reporte de falha quando a falha é inferida de sinais de alarme. |
| Localização de falhas e testes | Diagnostico interno
VPC/VCC capacidades de testes Loopback |
Tabela 7.2. Especificação de capacidades de gerenciamento
de falhas de ATM
Camada física defeito e detecção de falhas:
DSn e SONET interfaces, embora similar, possui algumas importantes diferencias em seus estados de falhas.
Vigilância de falhas para ATM sobre DS1 e DS3
Na camada física as seguintes falhas existem para sistemas de transmissões DS3 que são usados em PLCP para levar células ATM.
O estado PLCP LOF é definido persistente de PLCP fora do
frame (OOF) para 1 ms. PLCP LOF é declarado quando um error
ocorreu ambos A1 e A2 PLCP framing de octetos (figura 5.5) ou dentro
de dois consecutivamente inválidos, identificador de caminho
Overhead (POI) octetos.
As seguintes falhas existem para DS1 e DS2 sistemas que diretamente usam mapeamento de células em lugar de PLCP.
DS1 e DS3 alarme downstream inclui AIS. Alarme upstream inclui DS1 RDI e (PLCP é usado) PLCP alarme amarelo.
Vigilante alarme para ATM sobre SONET
Na camada física, as seguintes falhas existem para sistemas
de transmissão SONET que levam fluxos de células.
O estado LCD é um estado de especificação de
ATM. Aplicações de todos os sistemas de transmissão
que não usam PLCP.
Em operação normal, células são declaradas
(extraídas)para uma transmissão do payload. Depois
de iniciada a posição da primeira
célula é localizada. Contudo se as sete células
consecutivas tem um HEC (Header Error Controle) violações,
na saída da delineação de
célula (OCD) poderia ocurrir anomalias. A anomalia OCD
poderia confirmar até outras delimitações de outras
delineações de células
restabelecendo ou fazendo a transmissão dentro do estado
de defeito LCD.
Camada ATM defeito e detecção de falhas.
As falhas podem ser detectadas na camada ATM a partir da camada física de notificação de falhas
VP/VC indicações de alarme:
No nível ATM, dois indicações de alarme podem
ser definidas:
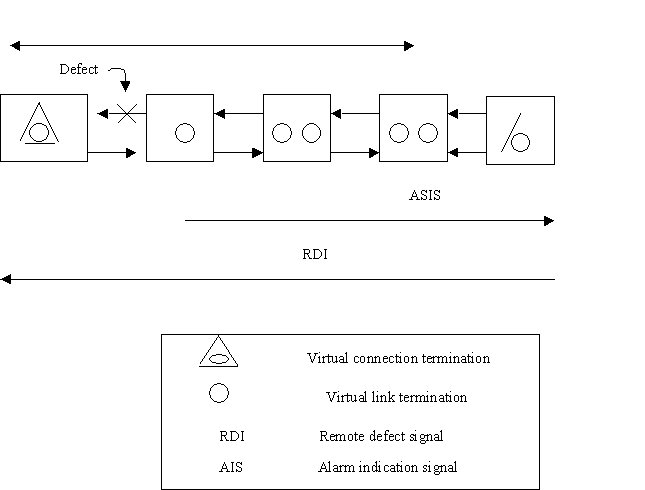
A
figura 7.1 mostra o fluxo de VP/VC AIS e alarme RDI o gerenciamento de
falhas contem campos que notam os tipos de falhas
e localização de falha.
Alarmes VP
A falha VPC pode ser detectada na camada ATM por recebimento e
indicações da camada física ou por recebimentos e
indicações da
entidade ATM.
1. Ponto de conexão de falha: Quando
o defeito e declarado na camada ATM a conexão de pontos, células
AIS são geradas e
periodicamente enviadas
downstream para cada VPC afeitado pela falha. A primeira célula
é enviada entre 50 e 500 ms depois de
uma indicação
de defeito. O limite inferior de 50 ms foi escolhido para permitir
a proteção do switching antes da geração das
células
AIS. O limite superior
de 500 ms. É requerido para suportar sinalização de
canais para prover um tempo de detecção de defeitos
para canais de sinalização.
2. Origem de pontos de falhas: Quando
o origem do defeito e detectado em um ponto final, e o mesmo procedimento,
que recebimento
de RD no ponto final são
ignorados (com um estado RDI).
3. Pontos terminais da falhas: Quando
o defeito e detectado no final de uma terminação o procedimento
em alguns casos de conexões,
exeto nas células
que são VP AIS.
Figura 7.1 Indicações de alarmes
VC Alarme
Falhas VCC podem ser detectadas na camada ATM por indicações
na camada física, ou por indicações de ponto terminais
VPC. A diferencia
de alarme VP, alarme VC não são gerados por todos
os VCCs, só por preselecção de conexões.
Todos os VCCs permitem fazer alarme
desejados, ambos permitem supressão de alarme onde não
seja desejada. Se VC-AIS é gerado, nesse caso o ponto final
também gera a VC-RDI.
A iteração de alarme VP entre VC é
mostrada na figura 7.2.
O estado de transição, o fluxo de VC-AIS, células
VC-RDI e o tempo de VCC com falhas são VPCs exeto à
geração de alarme para a VCC é
opcional.
O nível físico (DSN/SONET) o alarme indica muitos
resultados em geração de indicações de alarme
VPC, que em termo de muitos resultados
em geração de indicações de alarme VCC.
Esta interação de SONET e o nível de alarme ATM é
ilustrado na figura 7.3. Esta propagação de pontos
de alarmes necessitam de funções de correlação
de alarme em gerenciamento de sistemas de redes para identificar à
causa-efeito da relação e
simplicidade de retificação de processos.
Estrutura de células payload AIS/RDI
A estrutura de células payload AIS/RDI é mostrado
na figura 7.4 correntemente ambas ITU e T1 podem estandardizar o tamanho
de falhas com
tipo de campos de 8 bits. Com o tempo de escritura, ITU pode
não concordar com o tamanho da falha e localização
do campo. Cada campo é
descrito a seguir.

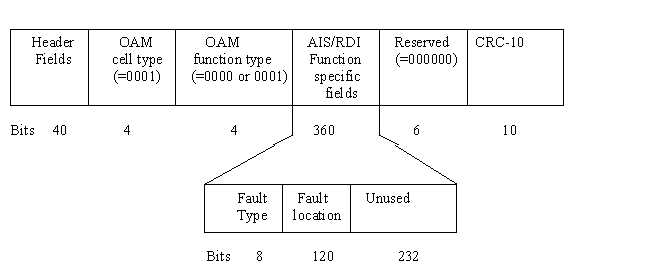
Figura 7.4 Gerenciamento de falhas OAM formato de cèlulas
AIS/RDI

Figura 7.5 Operação de Loopback

Figura 7.6 Gerenciamento de falhas Loopback em células com formato
OAM
Reportagem de falha quando uma falha é detectada
Uma entidade pode ser automaticamente restabelecida de defeitos
em curtos períodos de tempos, consequentemente, uma transição
dentro
de ume estado de defeito poderia não resultar geração
de reporte para gerenciamento de sistemas ou a remoção
de entidades de serviços.
Para assegurar este, um mecanismo de tempo de atraso é
usado.
Falhas específicas de ATM são declaradas só
depois da persistência de um defeito para um intervalo especifico,
Uma vez declarada a falha,
a indicação dela falhas é um conjunto de NE.
Quando NE detecta a falha, este é reportado por um apropriado
gerenciamento de sistema
como um alarme, e imediatos requerimentos são atendidos por
um apropriado sistema de gerenciamento.
Um baixo nível de falhas, tais como sistemas de transmissão
LOF, podem causar múltiplas indicações de falhas de
alto nível. Quando uma
entidade detecta uma falhas, este reporta ou disminuie o nível
de falha.
Uma diminuição relevante de nível de defeitos e falhas para cada tipo de interface são:
Reportagem de falhas quando a falha e inferido
a partir de sinalização de alarme
Se NE tem sido informado primeiro de detecção
de estado de defeitos ao entrar AIS ou RDI, e se o defeito persiste,
a entrada AIS
ou RDI e reportado como um estado de falha. Estados de falhas
AIS ou RDI podem não ser automaticamente reportadas, contudo,
pode estar disponível e recuperável por sistemas de gerenciamento.
Em qualquer rede, e desejável que o sistema de gerenciamento
não reciba reduncancia AIS e RDI de notificação
de defeitos.
Estos podem ser realizados por reportagens de falhas AIS e RDI
só para ingressos de redes, isto é em UNIs na chegada da
direções.
Localização de falhas e testes
Identificações de funções de testes
podem ser usados para isolar elementos de falhas de redes internas
baixando a "smallest"
reparável/substituível de software e hardware.
Em adição se capacidades identificáveis habilitadas
de redes que provêm testes de
execução sobre VPCs e VCCs individuais. Relatos
de diagnósticos internos para vendedores específicos, de
aspectos de NE,
testes de capacidades de VPC/VCC são genéricos.
Capacidade de Loopback OAM
Identificações de dificuldades em particular VPC/VCC
podem ter forma de dados de monitoramento de desempenho ou procedimentos
de vigilância de alarme, ou dificuldades de clientes de reportes
que indicam dificuldades de experiências em VPC/VCC em particular.
Sobre o recibo de dificuldades de reportes os testes podem ser
inicializados verificando a existência de problemas reportados identificando
a natureza do problema, e isolando a causa.
A capacidade OAM loopback pode ser usuada para:
? Verificação de conectividades
? Isolamento de falhas
? Desempenho de preserviço de testes aceitáveis
Células loopback OAM são executadas por inserções
de gerenciamento de falhas de células loopback em um ponto
ao largo da conexão,
com instruções de células payload para células
que ham sido looped back em outros ponto da conexão.
Gerenciamento de configuração
Capacidades gerais:
Referencia de gerenciamento de configuração para
identificações de funções. Coletam dados sobre
controle de exercício, e abastecem
de elementos de dados para á rede.
Existem outros System-driven de gerenciamento ou elementos de
redes (e.g, switch-driven ) por exemplo sistemas de gerenciamento
de configuração system-driven é um sistema de
configuração cross-connection que requer um switch.
Por exemplo, gerenciamento de configuração NE-driven
é uma reportagem NE para sistemas de gerenciamento sobre instalações
físicas
de cartões de interfaces. A principal função
de gerenciamento de configuração, em nível ATM do
switch, (privada ou pública)são
resumidas na tabela 7.4 e 7.5
A recomendação ITU-T M.3010 identifica as seguintes
funções de gerenciamento de configuração para
switchs ATM.
Referências
[2] D. Minoli, M. Vitella, Cell Relay Service and ATM in Corporate Environments, (McGraw-Hill, 1994)
[3] Bellcore Techinical Advisor TA-NWT-001248, Generic Requirements for Operations of Broadband Switching Systems, October, 1993.
[4] ITU-T Recomendation T.356. Geneva, CH
[5] Dan Minoli, Tom Golway with Norris Smith. Planning and Managing ATM Networks, Manning, 1997.