



Next: Técnicas de IA
Up: Detección de intrusos
Previous: Clasificación de comportamiento
Las técnicas que se suelen usar son:
- Técnicas estadísticas. Se usan en sistemas como NIDES[AFV95]. El sistema detector de anomalías observa la actividad de los sujetos y
genera modelos para la representación de su comportamiento. Los modelos se dise nan para que empleen poca cantidad de memoria para almacenar sus
estados internos, su actualización debe ser sencilla puesto que puede llevarse a cabo después de cada audit. Los registros de los audits se
procesan y el sistema genera periódicamente un valor que es la medida de la ``anormalidad'' del modelo. Existen varias medidas que forman parte
de estos modelos:
- Medidas de la intensidad de actividad.
- Cuantifica la tasa a la que se procesa la actividad. Se trata de detectar comportamiento
anormal en los ``picos'' de las medidas que pueden enmascararse en las medidas de las medias. Un ejemplo puede ser el número de registros de
audit procesados para un usuario en un minuto.
- Medidas de distribución de los registros de los audits.
- Calcula la distribución de todos los tipos de actividad en registros de audit
recientes. Un ejemplo puede ser la distribución relativa del acceso a ficheros y las actividades de E/S en el sistema para un usuario particular.
- Medidas en categorías.
- Mide la distribución de una actividad particular en distintas categorías, como la frecuencia relativa de los
accesos para una determina localización física, el uso relativo del correo electrónico, compiladores, shells, y editores del sistema.
Cuentan el número de veces que se da una actividad.
- Medidas normales.
- Como el tiempo de CPU, los recursos de E/S que usa un determinado usuario.
El problema de estos sistemas es que pueden no detectar intrusiones que se producen a partir de eventos individuales secuenciales e interrelacionados,
los sistemas estadísticos pueden entrenarse hasta el punto en el que el comportamiento antes considerado anormal puede pasar por uno normal. Por
tanto los sistemas basados en estos modelos combinan también un sistema de detección de abuso para observar la aparición de modelos específicos de eventos. Es difícil calcular los umbrales a partir de los cuales un comportamiento puede caracterizarse como normal o intrusivo. Existe un límite de
modelos de comportamiento que pueden ser detectados a partir de un sistema puramente estadístico.
- Generación predictiva de patrones. Se basa en la hipótesis que la secuencia de eventos no es aleatoria sino que sigue un modelo determinado.
Esto permite un mejor sistema de detección porque tiene en cuenta la relación y orden entre los distintos eventos. Estos sistemas usan reglas
variables en el tiempo que caracterizan los modelos de comportamiento normales. Las reglas se generan inductivamente, se modifican dinámicamente
durante la fase de aprendizaje y únicamente las ``buenas reglas'', con alto nivel de exactitud en la predicción y un alto nivel de confidencia
permanecen en el sistema. Una regla tiene una alta exactitud en la predicción si es correcta la mayor parte del tiempo, y posee un alto nivel de
confidencia si puede aplicarse con éxito en los datos observados. Un ejemplo de regla generado por el sistema TIM[TCL90] puede ser:
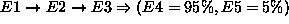
donde E1-E5 son eventos de seguridad. Esta regla que se basa en los datos observados previamente, indica que si se dan los eventos E1, seguido
de E2 seguido de E3, la probabilidad de observar E4 es 94% y la de E5 es del 5%.
Se genera un conjunto de reglas inductivamente observando el comportamiento del usuario frente al modelo del mismo. Se detectará una posible
desviación si la secuencia de eventos coincide en la parte izquierda y derecha pero los eventos siguientes de desvían mucho de aquellos que
predice la regla.
- Redes neuronales. La forma básica de funcionamiento es el entrenamiento de la red a partir de una secuencia de unidades de
información cada una de estas unidades puede de ser más abstracta que en registro de un programa de audit. La entrada de la red está
formada por el comando en un determinado instante y aquellos w comandos ejecutados anteriormente. Con estos comandos la red va a tratar de
predecir el que va a ser tecleado. Una vez que se entrena la red, se construye el modelo del usuario a partir de un conjunto de comandos representativos
y la fracción de eventos no predichos es, de alguna forma, la varianza del comportamiento del usuario con respecto a su modelo. El tama no de la
ventana de comandos es una variable independiente y debe tener el valor adecuado para que el sistema no sea demasiado pobre, si es muy peque na
o tenga información superflua, si es demasiado grande.
- Clasificación Bayesiana. La clasificación bayesiana se describe en[CHS91], es una técnica no supervisada de clasificación de
datos. Estas técnicas intentan determinar el proceso más parecido que genera los datos. No divide los datos en clases pero define una función
probabilística de pertenencia a cada clase de datos.
Next: Técnicas de IA
Up: Detección de intrusos
Previous: Clasificación de comportamiento
Celestino Gomez Cid (adm)
Fri Mar 22 16:20:52 MET 1996